什么是service
service是k8s的流量负载组件中的一种,常用的流量负载组件有以下几种
- service : 4层路由的负载
- ingress:7层路由的负载
什么需要用到service
在创建pod的时候,pod中的ip地址不是固定的,也就不能直接对pod的ip进行访问; 为了解决这个问题,k8s提供了流量负载组件service,
service会将多个pod进行聚合起来,提供一个统一的入口ip地址,通过service提供的统一入口就可以访问内部的pod资源了;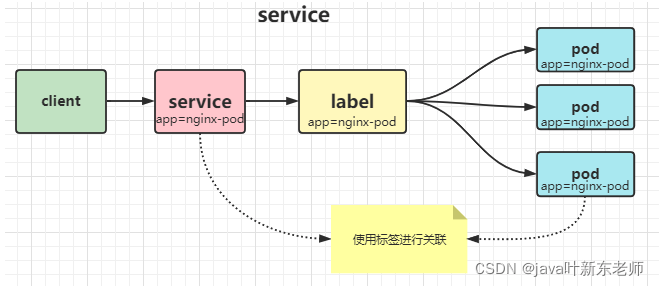
配置ipvs功能(已配置请略过)
在Kubernetes中Service有两种带来模型,一种是基于iptables的,一种是基于ipvs的两者比较的话,ipvs的性能明显要高一些,但是如果要使用它,需要手动载入ipvs模块;==注意:需要在每个节点都配置==
1.安装ipset和ipvsadm
yum install ipset ipvsadmin -y
2.添加需要加载的模块写入脚本文件
cat <<EOF> /etc/sysconfig/modules/ipvs.modules#!/bin/bashmodprobe -- ip_vsmodprobe -- ip_vs_rrmodprobe -- ip_vs_wrrmodprobe -- ip_vs_shmodprobe -- nf_conntrack_ipv4EOF
3.为脚本添加执行权限
chmod +x /etc/sysconfig/modules/ipvs.modules
4.执行脚本文件
/bin/bash /etc/sysconfig/modules/ipvs.modules
5.查看对应的模块是否加载成功
lsmod | grep -e ip_vs -e nf_conntrack_ipv4
一、service
Service在很多情况下只是一个概念,真正起作用的其实是kube-proxy服务进程,每个Node节点上都运行着一个kube-proxy服务进程。当创建Service的时候会通过api-server向etcd写入创建的service的信息,而kube-proxy会基于监听的机制发现这种Service的变动,然后它会将最新的Service信息转换成对应的访问规则。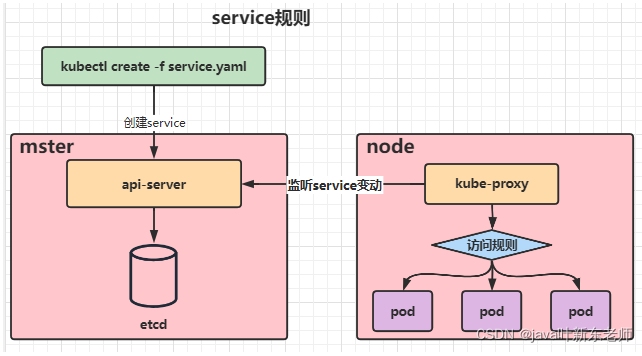
查看ipvs规则
# 10.97.97.97:80 是service提供的访问入口# 当访问这个入口的时候,可以发现后面有三个pod的服务在等待调用,# kube-proxy会基于rr(轮询)的策略,将请求分发到其中一个pod上去# 这个规则会同时在集群内的所有节点上都生成,所以在任何一个节点上访问都可以。[root@node1 ~]# ipvsadm -LnIP Virtual Server version 1.2.1 (size=4096)Prot LocalAddress:Port Scheduler Flags-> RemoteAddress:Port Forward Weight ActiveConn InActConnTCP 10.97.97.97:80 rr-> 10.244.1.39:80 Masq 1 0 0-> 10.244.1.40:80 Masq 1 0 0-> 10.244.2.33:80 Masq 1 0 0
kube-proxy工作模式
kube-proxy目前支持三种工作模式:
- userspace
- iptables
- ipvs
1、userspace 模式
userspace模式下,kube-proxy会为每一个Service创建一个监听端口,发向Cluster IP的请求被Iptables规则重定向到kube-proxy监听的端口上,kube-proxy根据LB算法选择一个提供服务的Pod并和其建立链接,以将请求转发到Pod上。 该模式下,kube-proxy充当了一个四层负责均衡器的角色。由于kube-proxy运行在userspace中,在进行转发处理时会增加内核和用户空间之间的数据拷贝,虽然比较稳定,但是效率比较低。
2、iptables 模式
iptables模式下,kube-proxy为service后端的每个Pod创建对应的iptables规则,直接将发向Cluster IP的请求重定向到一个Pod IP。 该模式下kube-proxy不承担四层负责均衡器的角色,只负责创建iptables规则。该模式的优点是较userspace模式效率更高,但不能提供灵活的LB策略,当后端Pod不可用时也无法进行重试。
3、ipvs 模式
ipvs模式和iptables类似,kube-proxy监控Pod的变化并创建相应的ipvs规则。ipvs相对iptables转发效率更高。除此以外,ipvs支持更多的LB算法。
开启 ipvs 模式
# 此模式必须安装ipvs内核模块,否则会降级为iptables# 开启ipvs,修改mode: "ipvs"[root@k8s-master01 ~]# kubectl edit cm kube-proxy -n kube-system# 需要重启下,因为有deployment在,所以直接删除pod后会重启一个新的pod[root@k8s-master01 ~]# kubectl delete pod -l k8s-app=kube-proxy -n kube-system# 查看ipvs[root@node1 ~]# ipvsadm -LnIP Virtual Server version 1.2.1 (size=4096)Prot LocalAddress:Port Scheduler Flags-> RemoteAddress:Port Forward Weight ActiveConn InActConnTCP 10.97.97.97:80 rr-> 10.244.1.39:80 Masq 1 0 0-> 10.244.1.40:80 Masq 1 0 0-> 10.244.2.33:80 Masq 1 0 0
service配置模板
kind: Service # 资源类型apiVersion: v1 # 资源版本metadata: # 元数据name: service # 资源名称namespace: dev # 命名空间spec: # 描述selector: # 标签选择器,用于确定当前service代理哪些podapp: nginxtype: # Service类型,指定service的访问方式clusterIP: # 虚拟服务的ip地址sessionAffinity: # session亲和性,支持ClientIP、None两个选项ports: # 端口信息- protocol: TCPport: 3017 # service端口targetPort: 5003 # pod端口nodePort: 31122 # 主机端口
service类型
spec.type 是 service类型,支持以下几种类型:
- ClusterIP:默认值,它是Kubernetes系统自动分配的虚拟IP,只能在集群内部访问
- NodePort:将Service通过指定的Node上的端口暴露给外部,通过此方法,就可以在集群外部访问服务
- LoadBalancer:使用外接负载均衡器完成到服务的负载分发,注意此模式需要外部云环境支持
- ExternalName: 把集群外部的服务引入集群内部,直接使用
session亲和性
sessionAffinity是负载均衡的亲和性,亲和性有2种选项
- None:不使用亲和性
- ClientIP:使用客户端的IP来做亲和性,比如说,IP为 192.168.1.101的客户端第一次请求到了pod-A的容器中,那么以后这个IP:192.168.1.101的请求也都会请求到pod-A的容器;
Service使用
在使用service之前,首先利用Deployment创建出3个pod,注意要为pod设置app=nginx-pod的标签
1、创建deployment
创建deployment.yaml,内容如下:
apiVersion: apps/v1kind: Deploymentmetadata:name: pc-deploymentnamespace: devspec:replicas: 3selector:matchLabels:app: nginx-podtemplate:metadata:labels:app: nginx-podspec:containers:- name: nginximage: nginx:1.17.1ports:- containerPort: 80
创建
[root@k8s-master01 ~]# kubectl create -f deployment.yamldeployment.apps/pc-deployment created# 查看pod详情[root@k8s-master01 ~]# kubectl get pods -n dev -o wide --show-labelsNAME READY STATUS IP NODE LABELSpc-deployment-66cb59b984-8p84h 1/1 Running 10.244.1.39 node1 app=nginx-podpc-deployment-66cb59b984-vx8vx 1/1 Running 10.244.2.33 node2 app=nginx-podpc-deployment-66cb59b984-wnncx 1/1 Running 10.244.1.40 node1 app=nginx-pod# 为了方便后面的测试,修改下三台nginx的index.html页面(三台修改的IP地址不一致)# kubectl exec -it pc-deployment-66cb59b984-8p84h -n dev /bin/sh# echo "10.244.1.39" > /usr/share/nginx/html/index.html#修改完毕之后,访问测试[root@k8s-master01 ~]# curl 10.244.1.3910.244.1.39[root@k8s-master01 ~]# curl 10.244.2.3310.244.2.33[root@k8s-master01 ~]# curl 10.244.1.4010.244.1.40
2、创建clusterip类型的service
创建service-clusterip.yaml文件
apiVersion: v1kind: Servicemetadata:name: service-clusteripnamespace: devspec:selector:app: nginx-podclusterIP: 10.96.97.97 # service的ip地址,如果不写,默认会生成一个type: ClusterIPports:- port: 80 # Service端口targetPort: 80 # pod端口
创建
# 创建service[root@k8s-master01 ~]# kubectl create -f service-clusterip.yamlservice/service-clusterip created# 查看service[root@k8s-master01 ~]# kubectl get svc -n dev -o wideNAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTORservice-clusterip ClusterIP 10.97.97.97 <none> 80/TCP 13s app=nginx-pod# 查看service的详细信息# 在这里有一个Endpoints列表,里面就是当前service可以负载到的服务入口[root@k8s-master01 ~]# kubectl describe svc service-clusterip -n devName: service-clusteripNamespace: devLabels: <none>Annotations: <none>Selector: app=nginx-podType: ClusterIPIP: 10.97.97.97Port: <unset> 80/TCPTargetPort: 80/TCPEndpoints: 10.244.1.39:80,10.244.1.40:80,10.244.2.33:80Session Affinity: NoneEvents: <none># 查看ipvs的映射规则[root@k8s-master01 ~]# ipvsadm -LnTCP 10.97.97.97:80 rr-> 10.244.1.39:80 Masq 1 0 0-> 10.244.1.40:80 Masq 1 0 0-> 10.244.2.33:80 Masq 1 0 0# 访问10.97.97.97:80观察效果[root@k8s-master01 ~]# curl 10.97.97.97:8010.244.2.33
Endpoint
Endpoint是kubernetes中的一个资源对象,存储在etcd中,用来记录一个service对应的所有pod的访问地址,它是根据service配置文件中selector描述产生的。
一个Service由一组Pod组成,这些Pod通过Endpoints暴露出来,Endpoints是实现实际服务的端点集合。换句话说,service和pod之间的联系是通过endpoints实现的。
每创建一个service,k8s会自动创建一个同名的 Endpoint出来,可通过一下命令查看 endpoint
# 一定要加skubectl get endpoints -n dev
修改nginx html内容
为了方便测试,我们将pod容器中nginx的html文件分别改为pod-1、pod-2、pod-3
# 进入容器内部kubectl exec -it podId -n dev /bin/sh# 修改html文件echo "pod-1" > /usr/share/nginx/html/index.htmlecho "pod-3" > /usr/share/nginx/html/index.html# 退出容器exit
负载分发策略
对Service的访问被分发到了后端的Pod上去,目前kubernetes提供了两种负载分发策略:
- 如果不定义,默认使用kube-proxy的策略,比如随机、轮询
- 基于客户端地址的会话保持模式,即来自同一个客户端发起的所有请求都会转发到固定的一个Pod上,此模式可以使在spec中添加sessionAffinity:ClientIP选项(在上面有介绍)
# 查看ipvs的映射规则【rr 轮询】[root@k8s-master01 ~]# ipvsadm -LnTCP 10.96.97.97:80 rr-> 192.168.104.14:80 Masq 1 0 0-> 192.168.104.15:80 Masq 1 0 0-> 192.168.166.139:80 Masq 1 0 0# 循环访问测试[root@k8s-master01 ~]# while true;do curl 10.96.97.97:80; sleep 5; done;pod-1pod-2pod-3pod-1pod-2pod-3pod-1# 修改分发策略 修改sessionAffinity:ClientIPkubectl edit service service-clusterip -n dev# 查看ipvs规则【persistent 代表持久】[root@k8s-master01 ~]# ipvsadm -LnTCP 10.96.97.97:80 rr persistent 10800-> 192.168.104.14:80 Masq 1 0 0-> 192.168.104.15:80 Masq 1 0 0-> 192.168.166.139:80 Masq 1 0 0# 循环访问测试[root@k8s-master01 ~]# while true;do curl 10.97.97.97; sleep 5; done;pod-2pod-2pod-2pod-2pod-2pod-2pod-2
3、删除service
# 删除service[root@k8s-master01 ~]# kubectl delete -f service-clusterip.yamlservice "service-clusterip" deleted
HeadLiness类型的Service
在某些场景中,开发人员可能不想使用Service提供的负载均衡功能,而希望自己来控制负载均衡策略,针对这种情况,kubernetes提供了HeadLiness Service,这类Service不会分配Cluster IP,如果想要访问service,只能通过service的域名进行查询。
创建service-headliness.yaml
apiVersion: v1kind: Servicemetadata:name: service-headlinessnamespace: devspec:selector:app: nginx-podclusterIP: None # 将clusterIP设置为None,即可创建headliness Servicetype: ClusterIPports:- port: 80targetPort: 80
创建
# 创建service[root@k8s-master01 ~]# kubectl create -f service-headliness.yamlservice/service-headliness created# 获取service, 发现CLUSTER-IP未分配[root@k8s-master01 ~]# kubectl get svc service-headliness -n dev -o wideNAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTORservice-headliness ClusterIP None <none> 80/TCP 11s app=nginx-pod# 查看service详情[root@k8s-master01 ~]# kubectl describe svc service-headliness -n devName: service-headlinessNamespace: devLabels: <none>Annotations: <none>Selector: app=nginx-podType: ClusterIPIP: NonePort: <unset> 80/TCPTargetPort: 80/TCPEndpoints: 10.244.1.39:80,10.244.1.40:80,10.244.2.33:80Session Affinity: NoneEvents: <none># 查看域名的解析情况[root@k8s-master01 ~]# kubectl exec -it pc-deployment-66cb59b984-8p84h -n dev /bin/sh/ # cat /etc/resolv.confnameserver 10.96.0.10search dev.svc.cluster.local svc.cluster.local cluster.local[root@k8s-master01 ~]# dig @10.96.0.10 service-headliness.dev.svc.cluster.localservice-headliness.dev.svc.cluster.local. 30 IN A 10.244.1.40service-headliness.dev.svc.cluster.local. 30 IN A 10.244.1.39service-headliness.dev.svc.cluster.local. 30 IN A 10.244.2.33
NodePort类型的Service
在之前的样例中,创建的Service的ip地址只有集群内部才可以访问,如果希望将Service暴露给集群外部使用,那么就要使用到另外一种类型的Service,称为NodePort类型。NodePort的工作原理其实就是将service的端口映射到Node的一个端口上,然后就可以通过NodeIp:NodePort来访问service了。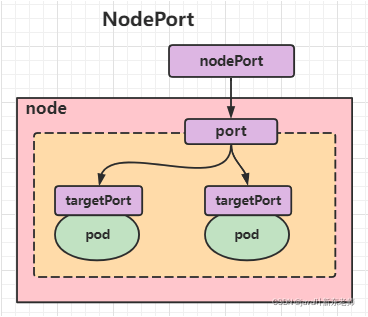
创建service-nodeport.yaml
apiVersion: v1kind: Servicemetadata:name: service-nodeportnamespace: devspec:selector:app: nginx-podtype: NodePort # service类型ports:- port: 80nodePort: 30002 # 指定绑定的node的端口(默认的取值范围是:30000-32767), 如果不指定,会默认分配targetPort: 80
创建
# 创建service[root@k8s-master01 ~]# kubectl create -f service-nodeport.yamlservice/service-nodeport created# 查看service[root@k8s-master01 ~]# kubectl get svc -n dev -o wideNAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) SELECTORservice-nodeport NodePort 10.105.64.191 <none> 80:30002/TCP app=nginx-pod# 接下来可以通过电脑主机的浏览器去访问集群中任意一个nodeip的30002端口,即可访问到pod,# 比如我的节点ip是:192.168.253.132,就可以用以下命令访问curl 192.168.253.132:30002
LoadBalancer类型的Service
LoadBalancer和NodePort很相似,目的都是向外部暴露一个端口,区别在于LoadBalancer会在集群的外部再来做一个负载均衡设备,而这个设备需要外部环境支持的,外部服务发送到这个设备上的请求,会被设备负载之后转发到集群中。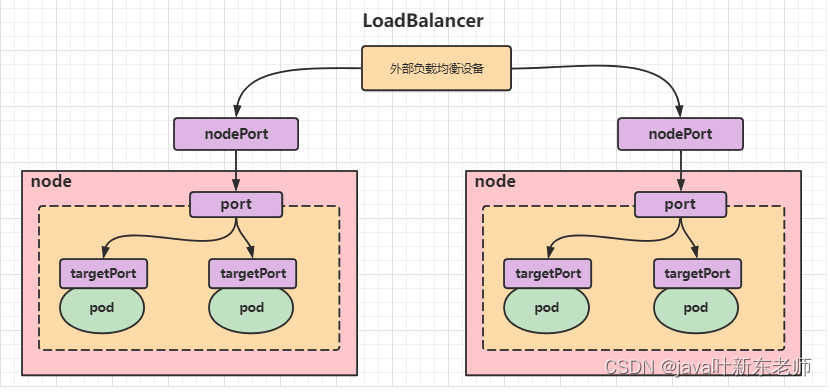
ExternalName类型的Service
ExternalName类型的Service用于引入集群外部的服务,它通过externalName属性指定外部一个服务的地址,然后在集群内部访问此service就可以访问到外部的服务了。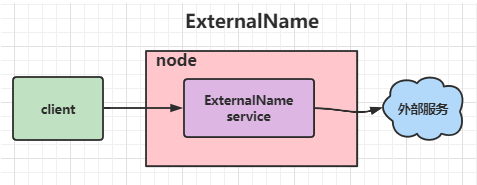
yaml文件内容如下
apiVersion: v1kind: Servicemetadata:name: service-externalnamenamespace: devspec:type: ExternalName # service类型externalName: www.baidu.com #改成ip地址也可以
创建
# 创建service[root@k8s-master01 ~]# kubectl create -f service-externalname.yamlservice/service-externalname created# 域名解析[root@k8s-master01 ~]# dig @10.96.0.10 service-externalname.dev.svc.cluster.localservice-externalname.dev.svc.cluster.local. 30 IN CNAME www.baidu.com.www.baidu.com. 30 IN CNAME www.a.shifen.com.www.a.shifen.com. 30 IN A 39.156.66.18www.a.shifen.com. 30 IN A 39.156.66.14
二、Ingress
在前面课程中已经提到,Service对集群之外暴露服务的主要方式有两种:NotePort和LoadBalancer,但是这两种方式,都有一定的缺点:
- NodePort方式的缺点是会占用很多集群机器的端口,那么当集群服务变多的时候,这个缺点就愈发明显
- LB方式的缺点是每个service需要一个LB,浪费、麻烦,并且需要kubernetes之外设备的支持
基于这种现状,kubernetes提供了Ingress资源对象,Ingress只需要一个NodePort或者一个LB就可以满足暴露多个Service的需求。工作机制大致如下图表示:
实际上,Ingress相当于一个7层的负载均衡器,是kubernetes对反向代理的一个抽象,它的工作原理类似于Nginx,可以理解成在Ingress里建立诸多映射规则,Ingress Controller通过监听这些配置规则并转化成Nginx的反向代理配置 , 然后对外部提供服务。在这里有两个核心概念:
- ingress:kubernetes中的一个对象,作用是定义请求如何转发到service的规则
- ingress controller:具体实现反向代理及负载均衡的程序,对ingress定义的规则进行解析,根据配置的规则来实现请求转发,实现方式有很多,比如Nginx, Contour, Haproxy等等
Ingress(以Nginx为例)的工作原理如下:
- 用户编写Ingress规则,说明哪个域名对应kubernetes集群中的哪个Service
- Ingress控制器动态感知Ingress服务规则的变化,然后生成一段对应的Nginx反向代理配置
- Ingress控制器会将生成的Nginx配置写入到一个运行着的Nginx服务中,并动态更新
- 到此为止,其实真正在工作的就是一个Nginx了,内部配置了用户定义的请求转发规则
Ingress的使用
1、环境准备 搭建ingress环境
# 创建文件夹[root@k8s-master01 ~]# mkdir ingress-controller[root@k8s-master01 ~]# cd ingress-controller/# 获取ingress-nginx,本次案例使用的是0.30版本[root@k8s-master01 ingress-controller]# wget https://raw.githubusercontent.com/kubernetes/ingress-nginx/nginx-0.30.0/deploy/static/mandatory.yaml[root@k8s-master01 ingress-controller]# wget https://raw.githubusercontent.com/kubernetes/ingress-nginx/nginx-0.30.0/deploy/static/provider/baremetal/service-nodeport.yaml# 修改mandatory.yaml文件中的仓库# 修改quay.io/kubernetes-ingress-controller/nginx-ingress-controller:0.30.0# 为quay-mirror.qiniu.com/kubernetes-ingress-controller/nginx-ingress-controller:0.30.0# 创建ingress-nginx[root@k8s-master01 ingress-controller]# kubectl apply -f ./# 查看ingress-nginx[root@k8s-master01 ingress-controller]# kubectl get pod -n ingress-nginxNAME READY STATUS RESTARTS AGEpod/nginx-ingress-controller-fbf967dd5-4qpbp 1/1 Running 0 12h# 查看service[root@k8s-master01 ingress-controller]# kubectl get svc -n ingress-nginxNAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGEingress-nginx NodePort 10.98.75.163 <none> 80:32240/TCP,443:31335/TCP 11h
2、准备service和pod
为了后面的实验比较方便,创建如下图所示的模型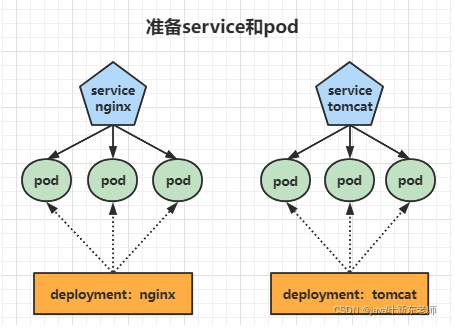
apiVersion: apps/v1kind: Deploymentmetadata:name: nginx-deploymentnamespace: devspec:replicas: 3selector:matchLabels:app: nginx-podtemplate:metadata:labels:app: nginx-podspec:containers:- name: nginximage: nginx:1.17.1ports:- containerPort: 80---apiVersion: apps/v1kind: Deploymentmetadata:name: tomcat-deploymentnamespace: devspec:replicas: 3selector:matchLabels:app: tomcat-podtemplate:metadata:labels:app: tomcat-podspec:containers:- name: tomcatimage: tomcat:8.5-jre10-slimports:- containerPort: 8080---apiVersion: v1kind: Servicemetadata:name: nginx-servicenamespace: devspec:selector:app: nginx-podclusterIP: Nonetype: ClusterIPports:- port: 80targetPort: 80---apiVersion: v1kind: Servicemetadata:name: tomcat-servicenamespace: devspec:selector:app: tomcat-podclusterIP: Nonetype: ClusterIPports:- port: 8080targetPort: 8080
创建
# 创建[root@k8s-master01 ~]# kubectl create -f tomcat-nginx.yaml# 查看[root@k8s-master01 ~]# kubectl get svc -n devNAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGEnginx-service ClusterIP None <none> 80/TCP 48stomcat-service ClusterIP None <none> 8080/TCP 48s
3、Http代理
创建ingress-http.yaml
apiVersion: extensions/v1beta1kind: Ingressmetadata:name: ingress-httpnamespace: devspec:rules:- host: nginx.itheima.comhttp:paths:- path: /backend:serviceName: nginx-serviceservicePort: 80- host: tomcat.itheima.comhttp:paths:- path: /backend:serviceName: tomcat-serviceservicePort: 8080
创建
# 创建[root@k8s-master01 ~]# kubectl create -f ingress-http.yamlingress.extensions/ingress-http created# 查看[root@k8s-master01 ~]# kubectl get ing ingress-http -n devNAME HOSTS ADDRESS PORTS AGEingress-http nginx.itheima.com,tomcat.itheima.com 80 22s# 查看详情[root@k8s-master01 ~]# kubectl describe ing ingress-http -n dev...Rules:Host Path Backends---- ---- --------nginx.itheima.com / nginx-service:80 (10.244.1.96:80,10.244.1.97:80,10.244.2.112:80)tomcat.itheima.com / tomcat-service:8080(10.244.1.94:8080,10.244.1.95:8080,10.244.2.111:8080)...# 接下来,在本地电脑上配置host文件,解析上面的两个域名到192.168.109.100(master)上# 然后,就可以分别访问tomcat.itheima.com:32240 和 nginx.itheima.com:32240 查看效果了
4、Https代理
# 生成证书openssl req -x509 -sha256 -nodes -days 365 -newkey rsa:2048 -keyout tls.key -out tls.crt -subj "/C=CN/ST=BJ/L=BJ/O=nginx/CN=itheima.com"# 创建密钥kubectl create secret tls tls-secret --key tls.key --cert tls.crt
创建ingress-https.yaml
apiVersion: extensions/v1beta1kind: Ingressmetadata:name: ingress-httpsnamespace: devspec:tls:- hosts:- nginx.itheima.com- tomcat.itheima.comsecretName: tls-secret # 指定秘钥rules:- host: nginx.itheima.comhttp:paths:- path: /backend:serviceName: nginx-serviceservicePort: 80- host: tomcat.itheima.comhttp:paths:- path: /backend:serviceName: tomcat-serviceservicePort: 8080
创建
# 创建[root@k8s-master01 ~]# kubectl create -f ingress-https.yamlingress.extensions/ingress-https created# 查看[root@k8s-master01 ~]# kubectl get ing ingress-https -n devNAME HOSTS ADDRESS PORTS AGEingress-https nginx.itheima.com,tomcat.itheima.com 10.104.184.38 80, 443 2m42s# 查看详情[root@k8s-master01 ~]# kubectl describe ing ingress-https -n dev...TLS:tls-secret terminates nginx.itheima.com,tomcat.itheima.comRules:Host Path Backends---- ---- --------nginx.itheima.com / nginx-service:80 (10.244.1.97:80,10.244.1.98:80,10.244.2.119:80)tomcat.itheima.com / tomcat-service:8080(10.244.1.99:8080,10.244.2.117:8080,10.244.2.120:8080)...# 下面可以通过浏览器访问https://nginx.itheima.com:31335 和 https://tomcat.itheima.com:31335来查看了


