面试经历
在很长的一段时间里,我以为缓存击穿和缓存穿透是一个东西,直到最近去腾讯面试,面试官问我缓存击穿和穿透的区别;我回答它俩是一样的,面试官马上抬起头用他那细长的单眼皮眼睛瞪着我说:“你确定吗?”,最后面试提醒我,既然有不同的名字,那他们肯定就是不一样的,也就是说缓存击穿和缓存穿透不是一个东西;
那么今天我们就看看这俩玩意的区别,以及它们引发的后果;
在项目中加入缓存
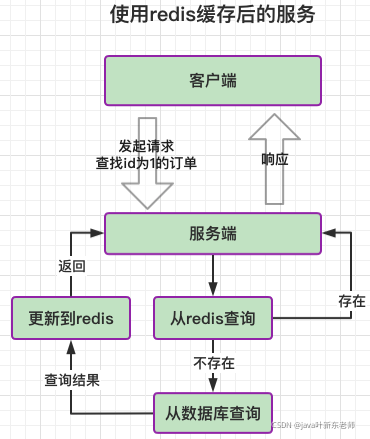
一般情况下,我们会把热点数据放到缓存中,比如常用的字典、用户信息、订单详情等等;也就是说,当项目启动后,先将热点数据加载到redis中,以后需要数据时就不用每次都去数据库查询了,这样一来,既减少了数据库的压力,也提升了访问速度,可谓是一举多得呀!
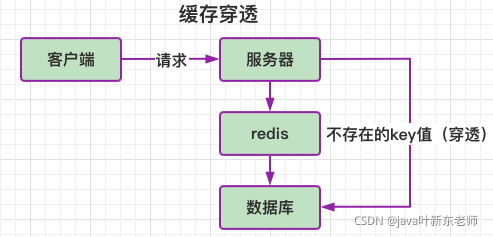
缓存穿透
缓存穿透是指缓存和数据库中都没有的数据,而用户不断发起请求,如发起为id为“-1”的数据或id为特别大不存在的数据。这时的用户很可能是攻击者,攻击会导致数据库压力过大。
解决方案:
- 接口层增加校验,如用户鉴权校验,id做基础校验,id<=0的直接拦截;
- 从缓存取不到的数据,在数据库中也没有取到,这时也可以将key-value对写为key-null,缓存有效时间可以设置短一些,如30秒(设置太长会导致正常情况也没法使用)。这样可以防止攻击用户反复用同一个id暴力攻击
- 使用布隆过滤器,需要安装redis组件
- 使用布谷鸟滤器,布谷鸟过滤器是布隆过滤器的升级版,需要安装redis组件
- 在客户端自行实现布隆过滤算法;
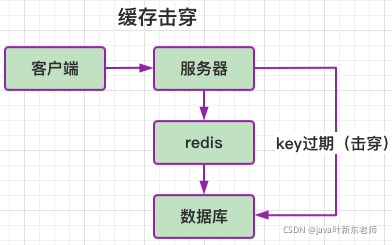
缓存击穿
缓存击穿指的是大量的key在同一时间过期,但是又有大量的请求需要用到这些已经过期的key,那么程序在redis找不到数据,就会去数据库里查询,数据库处理大量的请求的同时导致压力瞬间增大,造成压力过大,甚至导致崩溃;
解决方案
- 设置key值永不过期
- 将key的过期时间设为随机
- 使用布隆过滤器或者布谷鸟过滤器
使用分布式锁,当多个key过期时,同一时间只有一个查询请求下发到数据库,其他的key等待一个个地轮流查,就可以避免数据库压力过大的问题;代码如下:
// 分布式锁,为了可读性高用 ReentrantLock 代替分布式锁static Lock lock = new ReentrantLock();public String getData(String key ) throws InterruptedException {try {// 从redis获取值String data = getRedisData(key);// 如果key不存在,从数据库查询if(null == data){// 尝试获取锁if(!lock.tryLock()){// 获取锁失败 ,100ms后在次尝试TimeUnit.MILLISECONDS.sleep(100);data = getData(key);}// 走到这里表示成功获取锁// 从myqsl中获取锁data = getMysqlData(key);// 将数据更新到redissetDataToRedis(key,value);}return data;} catch (Exception e){e.printStackTrace();throw e;} finally {// 解锁lock.unlock();}}
穿透和击穿的区别
关于穿透和击穿的区别上面已经介绍的很清楚了,这里在做个总结
- 穿透 :大量请求了缓存和数据库中都没有的数据,每次都查询数据库,导致数据库压力过大
- 击穿 : 大量key在同一时间过期,导致所有请求都达到数据库,导致数据库压力过大
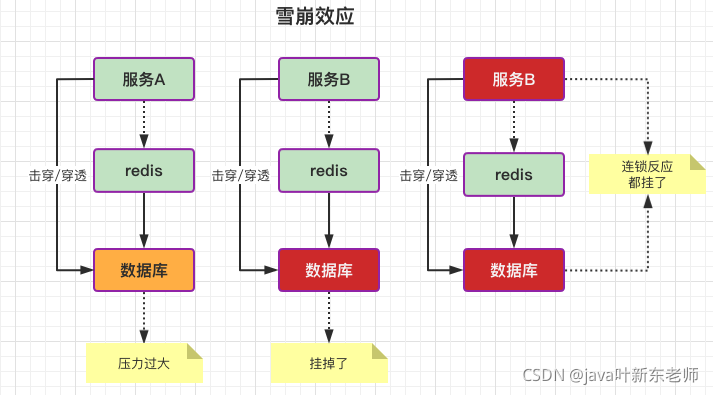
雪崩效应
雪崩效应指的是由穿透和击穿引起的数据库压力过大,最后导致整个数据库宕机,一旦数据库崩了,它所带来的连锁反应是可怕的,数据库不可用的情况下你的服务器也无法使用;这就是雪崩效应;