java是目前全球最火的语言,热度也是最高的,相信做开发的你肯定用过,那我就要问问,你仅仅是用过还是了解它的底层机制和执行原理呢?那么今天我们就揭开它神秘的面纱,看看jvm在我们开发的时候帮我们做了哪些事情;说到这里,有个小兄弟要问了:“我会用不就行了吗?了解它干啥呢?难不成我要自己写一个jvm出来?if 和 for 语句我用得可顺手,了解它的底层机制有卵用?”; 唉~ ,这位小兄弟,你先别急啊,首先呢,用只是基础,就像开发一样,增删改查就是一个开发人员的基础,难不成你想一辈子都干增删改查吗? 学习这些还不是为了让我们收入蹭蹭往上涨,让我们通往架构师的路越来越顺畅;安安静静地坐下来,让我们开始学习吧!
java虚拟机类加载过程
首选,项目启动后,jvm 会去加载每一个class字节码文件,将class内存加载到内存空间里面;内存空间主要分为四块,分别是 堆内存、java栈、本地方法栈、方法区(永久区),加载过程如下图:
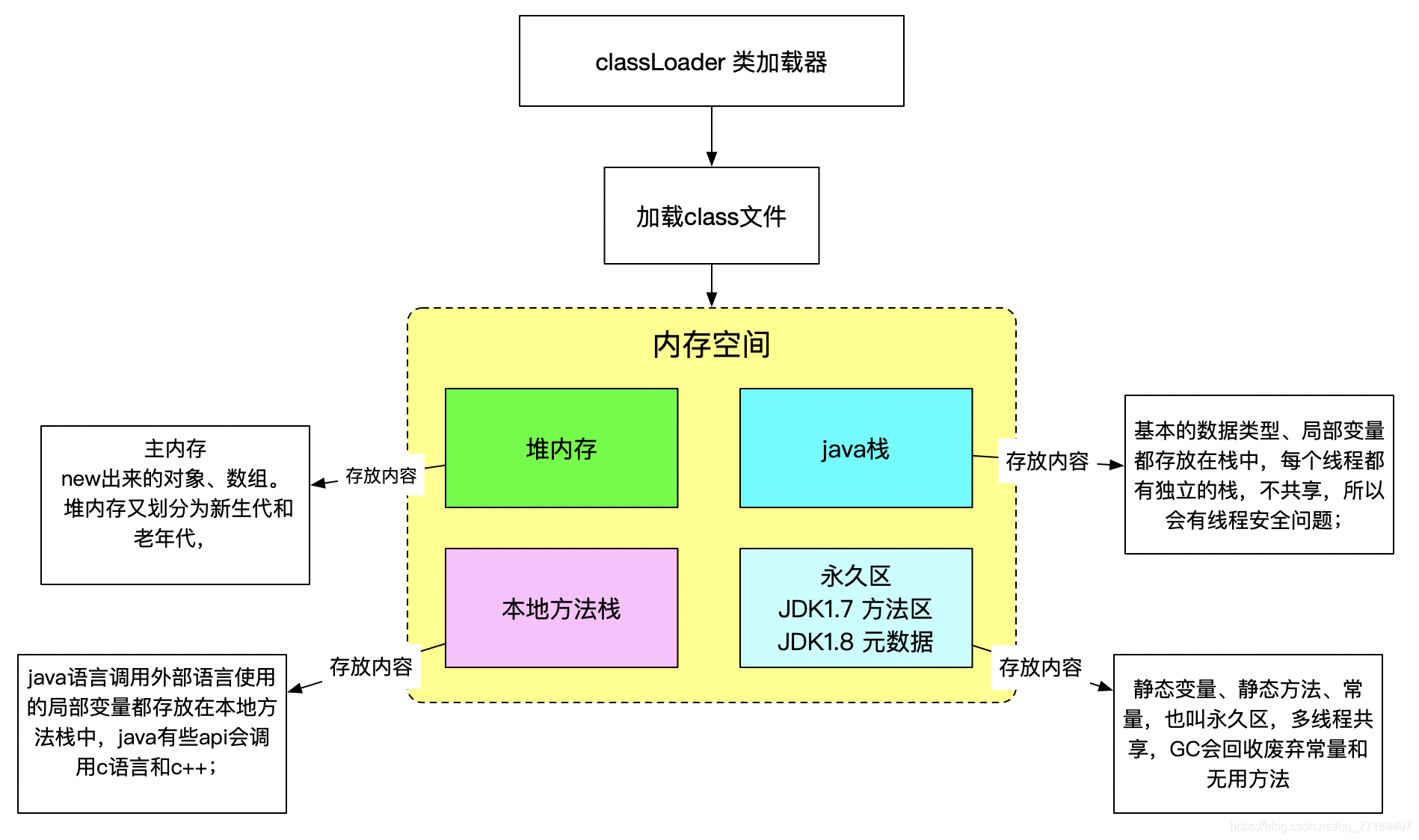
接下来我们看看内存空间里的每个东西都有什么作用
堆内存
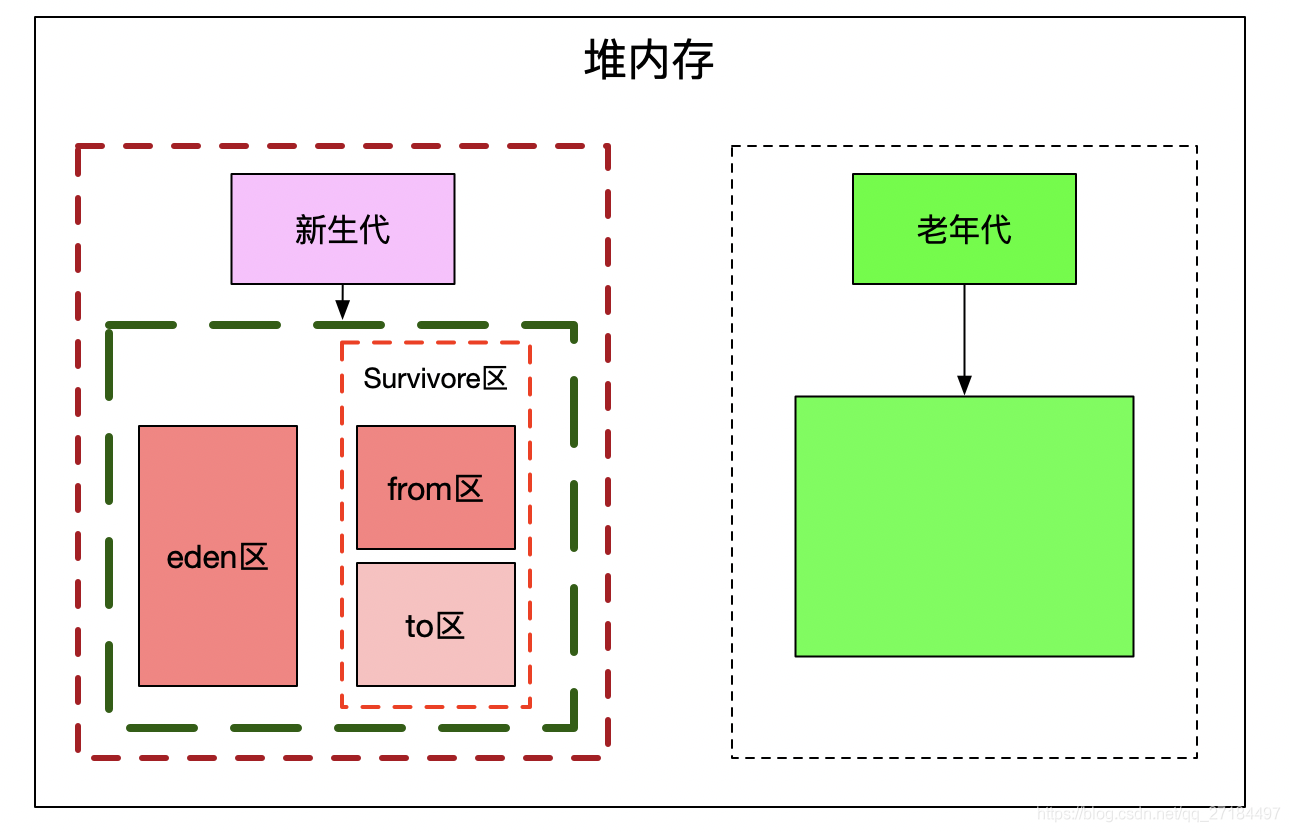
堆内存是java里面最主要的内存空间,只要是new出来的对象都是放在这里的,当然数组也是放在这个空间里面的,堆内存里面还包含新生代和老年代;
新生代(年轻代): 存放刚new出来的对象,新生代又划分为 eden 区和survivore区(幸存者),survivore区又划分为 form 区和 to 区,form区和 to 区的内存容量的大小是一样的,刚new出来的对象都会先放到Eden区,gc进行回收的时候发现new出来的对象经常被使用,就会晋升到survivore区,,下次GC清理时发现这个对象还是经常使用,就会晋升到老年代里面,其中 GC线程也是在新生代里面的;survivore区、 form 区、 to 区的比例为 8:1:1;
老年代:存放比较活跃的对象,GC回收的时候发现某个对象很活跃,Gc回收时发现这个对象超过一定次数了(jdk1.7默认是15次)还是很活跃,就会把这个对象晋升到老年代里面;老年代的内存很少回收,除非是内存满了才会进行回收;由 fullGC 进行回收;
堆内存结构图 ↓
java栈
java栈属于子线程专用的内存空间,存储基本数据类型和对象引用,每个线程都有自己独立的栈区,数据不共享;进栈(压栈)和出栈遵循先进后出的顺序
本地方法栈
java语言调用外部语言使用的局部变量都存放在本地方法栈中,java有些api会调用c语言或c++;
方法区(永久区)
方法区主要存储静态资源,比如 静态变量、静态方法、常量都是存储到方法区的;
PC寄存器(程序计数器)
当前线程所执行的字节码行号指示器,就是告诉你代码走到哪一行了;
GC Roots
说白了, GC Roots就是存储堆外指向对内的引用,java中的 栈、本地方法栈、方法区都可以作为GC Roots 的引用对象使用;当对象可达时,GC Roots就会有一个对这个对象的引用关系,如果没有此对象的引用,则被认为不可达,jvm的垃圾回收机制会将不可达的对象内存进行回收操作;
垃圾回收机制的种类
- Minor GC : 回收新生代空间
- Full GC : 回收老年代空间,Full Gc也能回收永久代空间,当永久代满了之后,或者是占用容量超过了你配置的临界值,就会触发完全垃圾回收 ,
- Major GC : 回收永久代空间,Full Gc也能回收永久代空间
GC什么时候回收?
垃圾回收机制是不定时回收的,可以调用System.gc();方法提示gc进行垃圾回收,但是这个方法仅仅是提醒gc进行回收,而不是强制回收;
另外,每个类都可以通过重写 finalize() 方法,这个方法可以在gc回收之前做一些操作,就是你想让垃圾回收之前执行哪些代码,使用时必须是Object 的子类,直接new Object(); 然后重写finalize方法不会执行 finalize 方法;
垃圾回收机制算法
接下来就要深入地去了解垃圾回收机制的算法了,让我们看看最底层是怎么进行回收内存的吧!
1、引用计数法 (已废弃--会产生循环依赖问题)
每个new 出来的对象都有一个年龄,默认0岁,每引用一次 + 1岁,Gc每扫描一次,发现没被引用,则会 - 1 岁,当到达一定岁数时,会晋升到老年代; 当岁数减至 0 时,Gc 会将其回收;下图说明了引用计数法的回收原理
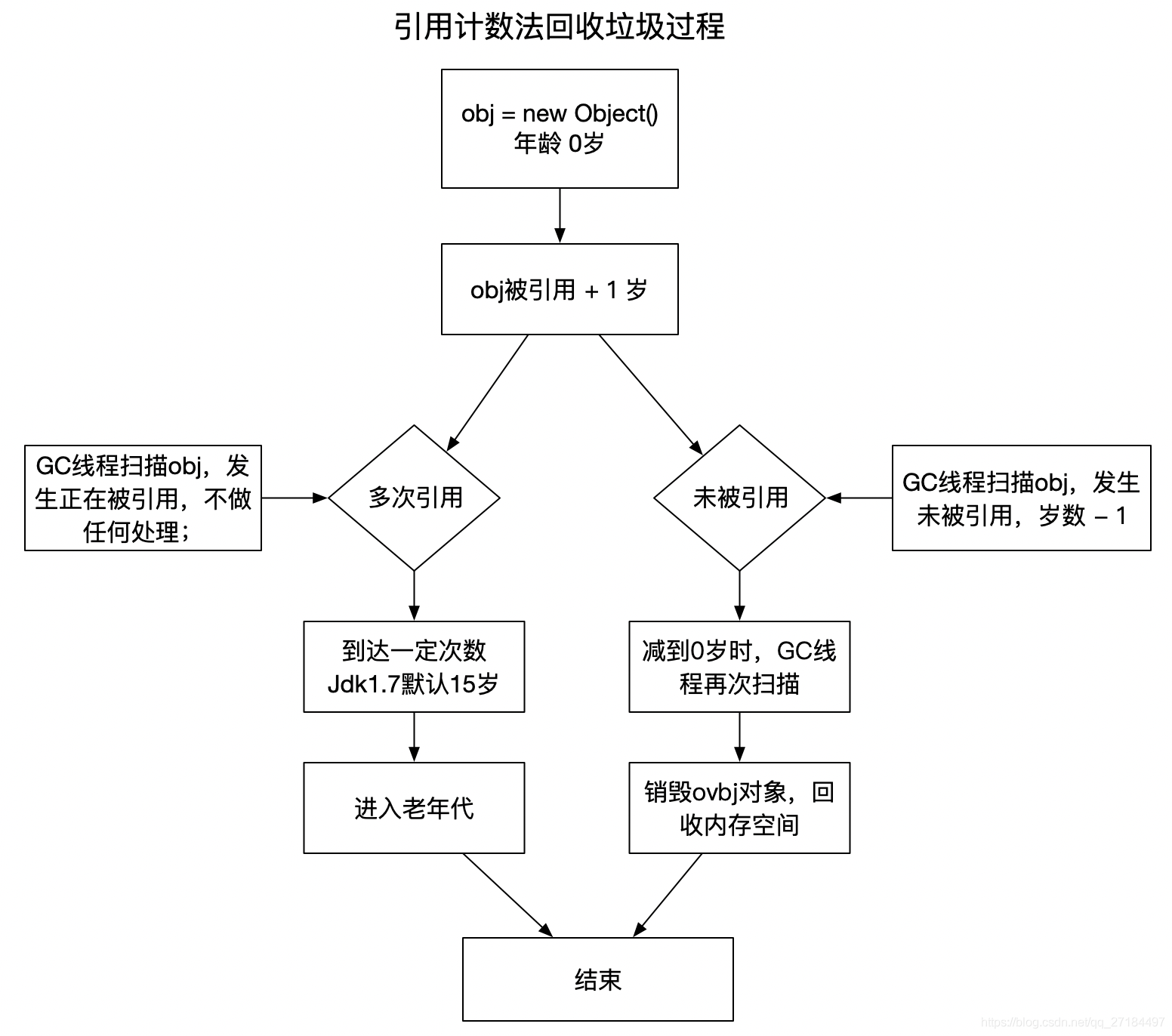
乍一看这个回收机制还挺好用的呀,为什么会废弃了呢?因为它无法解决循环依赖的问题,什么是循环依赖呢?我们先看看下面的代码
- public static void main(String[] args) {
- Test test_A = new Test();
- Test test_B = new Test();
-
- // 关键代码 循环依赖
- test_A = test_B;
- test_B = test_A;
-
- // 就算设置为null,gc还是不会回收,因为有循环依赖问题
- test_A = null;
- test_B = null;
-
- // 假设在这里进行回收,test_A和test_B都不会被gc回收,因为他们循环依赖了
- System.gc();
- }

通过上面的代码我们可以看到关键代码的部分一开始 test_A = test_B,然后又执行了test_B = test_A,这就会产生循环依赖问题,因为相互引用,在内部产生了闭环,就会导致它们的年龄永远不会为0,也就不会被gc回收;
2、标记清除算法(可解决循环依赖问题,但是会产生内存碎片化问题,一般用在老年代,)
要了解标记清除算法,我们得先理解一个概念,就是每个对象new 出来之后都有一个标记,这个标记有2种状态:
1:表示可达 (被引用);
0:表示不可达(未被引用);
对象new出来之后默认为 1 ,被引用后也为 1,GC 扫描对象后,如果发现obj正在被引用,则会将标记置为 1,GC扫描时如发现对象未被引用,则标记为 0。 随后GC会对循环遍历堆内存中标识为 0 的对象进行清理;整个清理过程如下
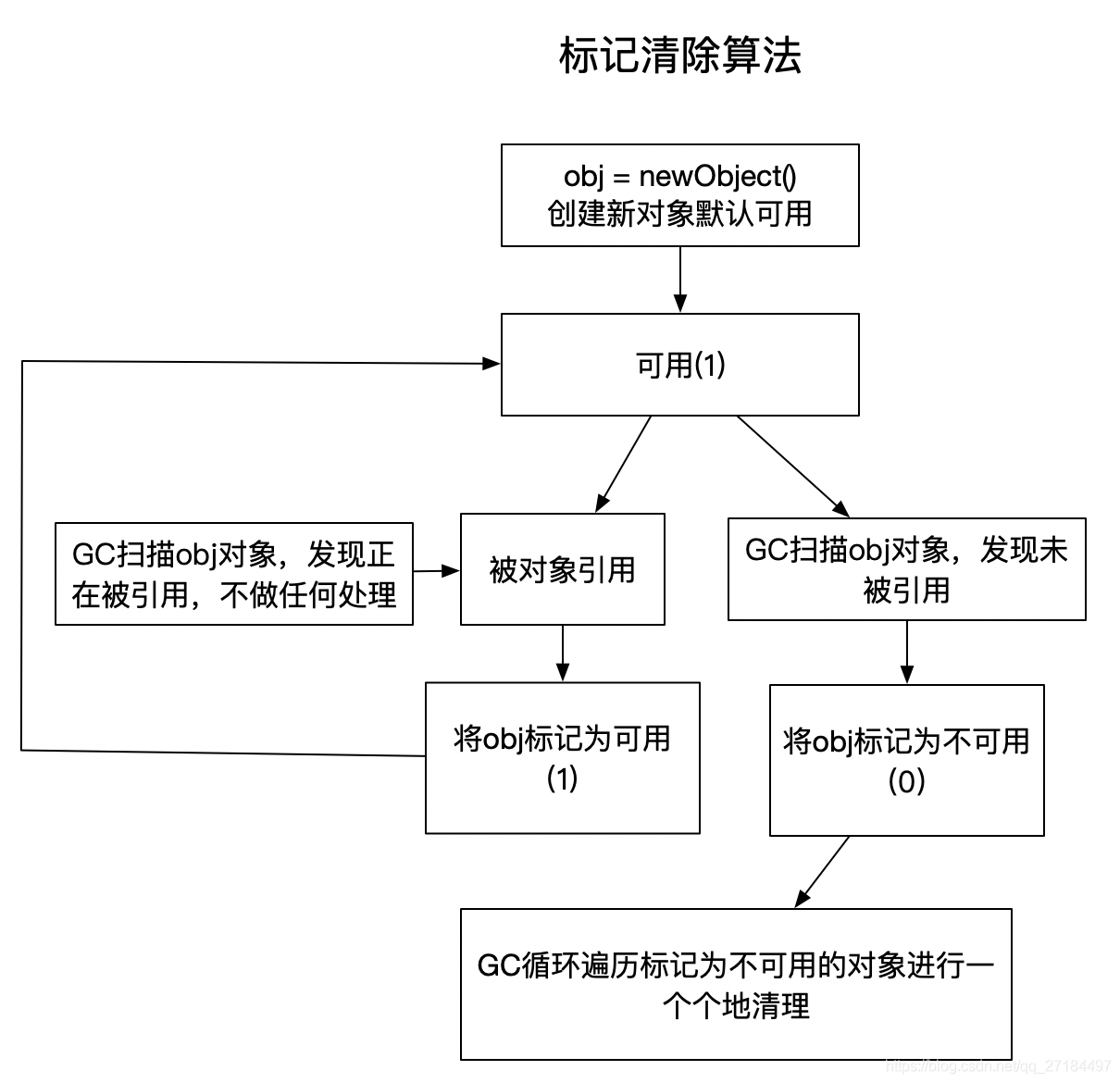
下图我们可以看到清除前和清除后的内存变化,其中绿色为可用对象,红色为不可用对象
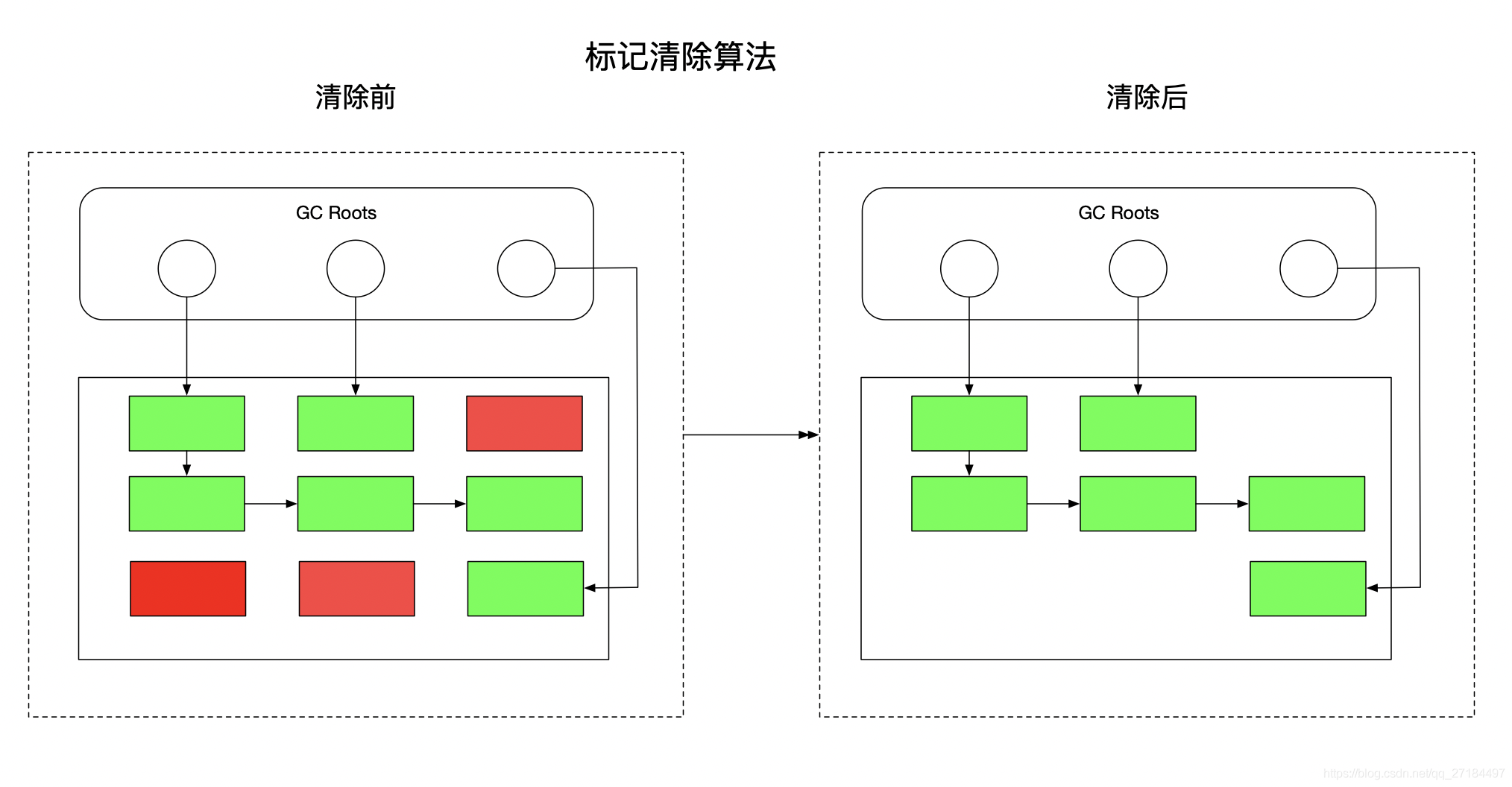
清理为什么会产生碎片化呢?
因为是循环遍历去清理的,也就是一个个地去删除,删除的同时也会有新的对象存进去,内存存储这些大小不一的对象是存储到不同的地方去,但是当GC清理对象的时候,虽然已经内存清理已经完成了,但是它仍然还有碎片残留在别的地方;这就产生了碎片化; 所以标记清除算法一般用在老年代里面,因为老年代回收的频率比较少,即使有一些碎片也无所谓!
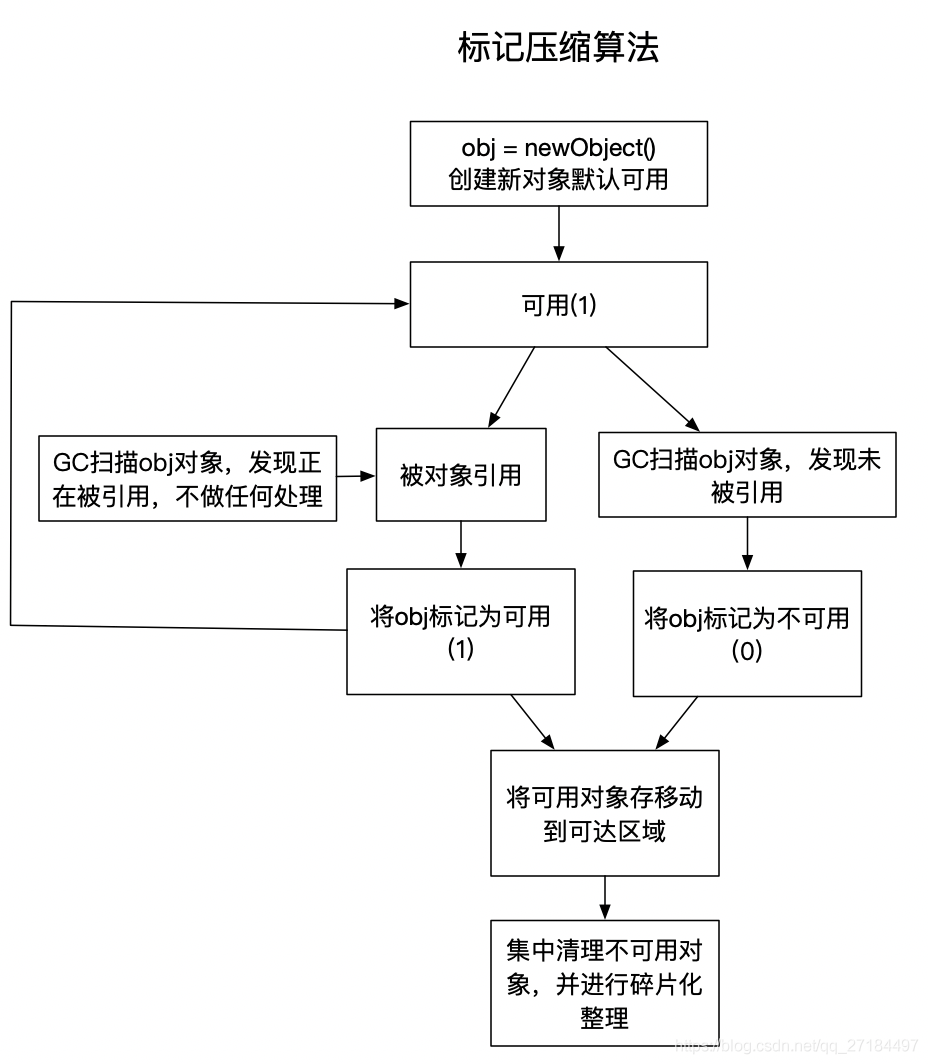
3、标记压缩算法(标记整理算法)
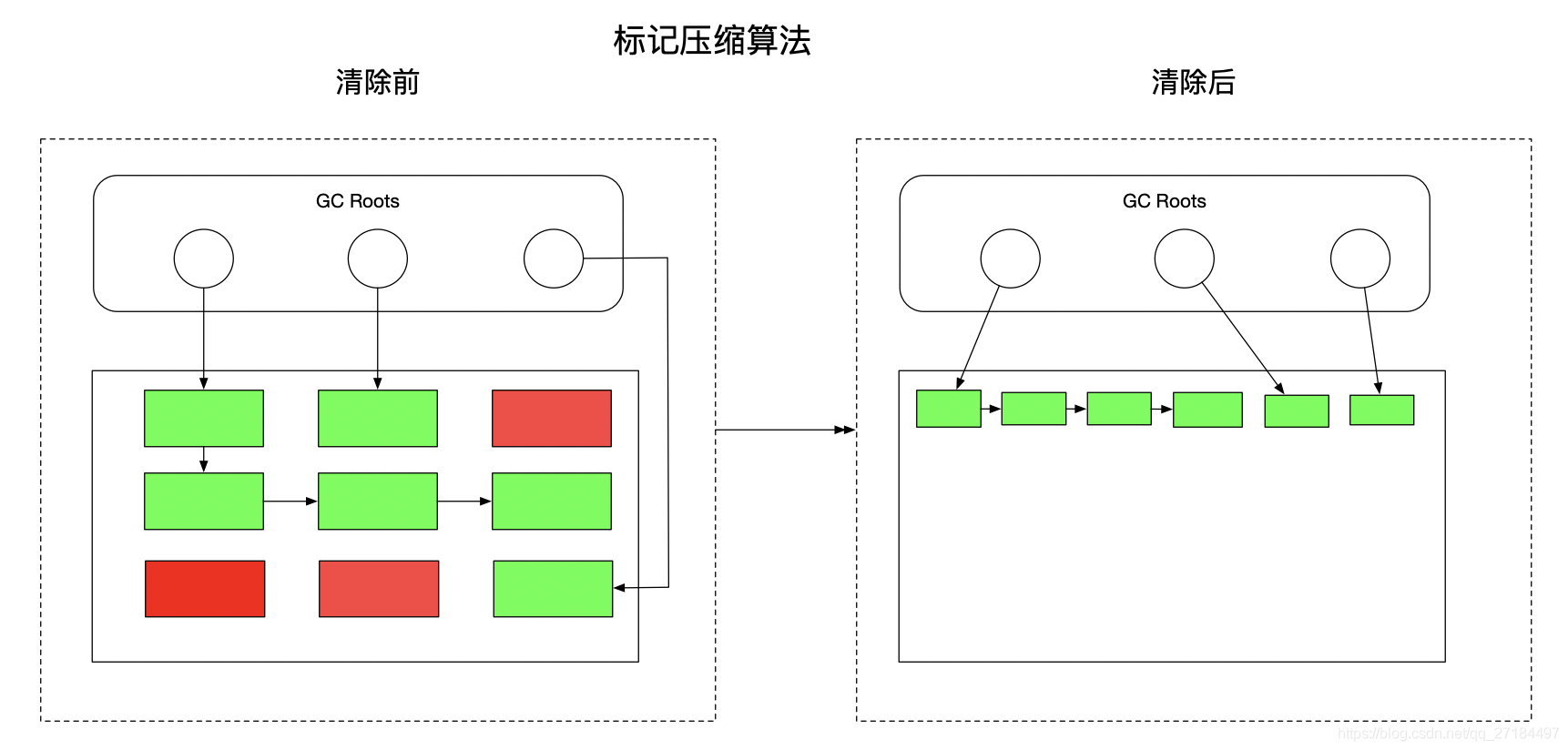
标记压缩算法其实是在标记清除算法的基础上进行改进的,有相似之处,重点是标记压缩算法可以解决内存碎片化的问题,压缩算法会将标记为可达对象移到到堆内存的同一个区域中,使它们紧凑地排列在一起,因为刚刚已经将可达对象移走了,所以剩下的就都是不可达对象了,这时候在进行集中清理不可达对象;相当于一把删除,在进行碎片化整理,这样就不会有碎片化的问题存在了,具体流程图如下;
下图为我们展示了标记压缩算法清理前和清理后的内存结构变化
4、根搜索算法
这个算法的基本思想是通过一系列称为“GC Roots”的对象作为起始点,从这些节点向下搜索,搜索所走过的路径称为引用链,当一个对象到GC Roots没有任何引用链(即GC Roots到对象不可达)时,则证明此对象是不可用的;GC Roots的引用链是一个树形结构,如下图:
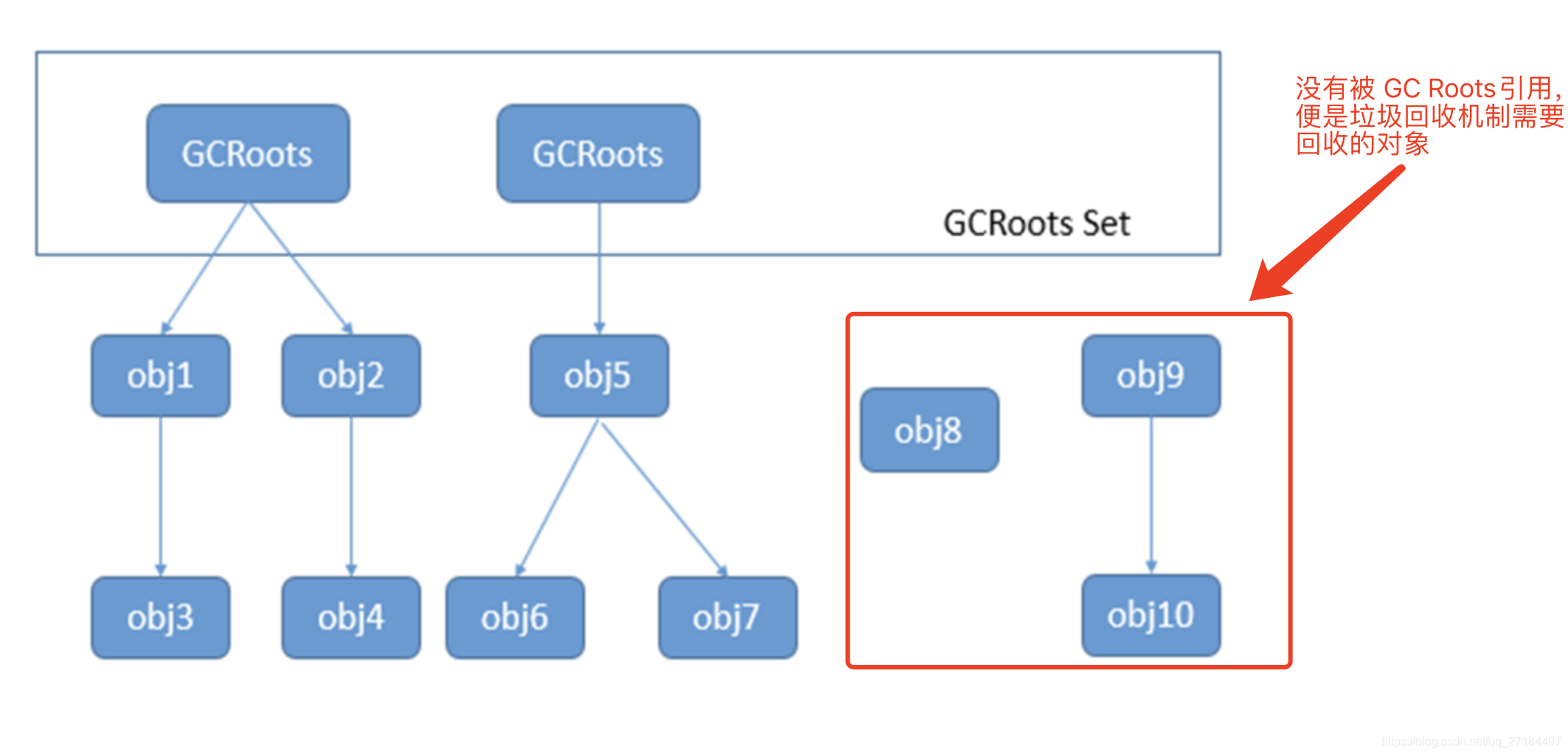
在看看下面的图进行具体分析
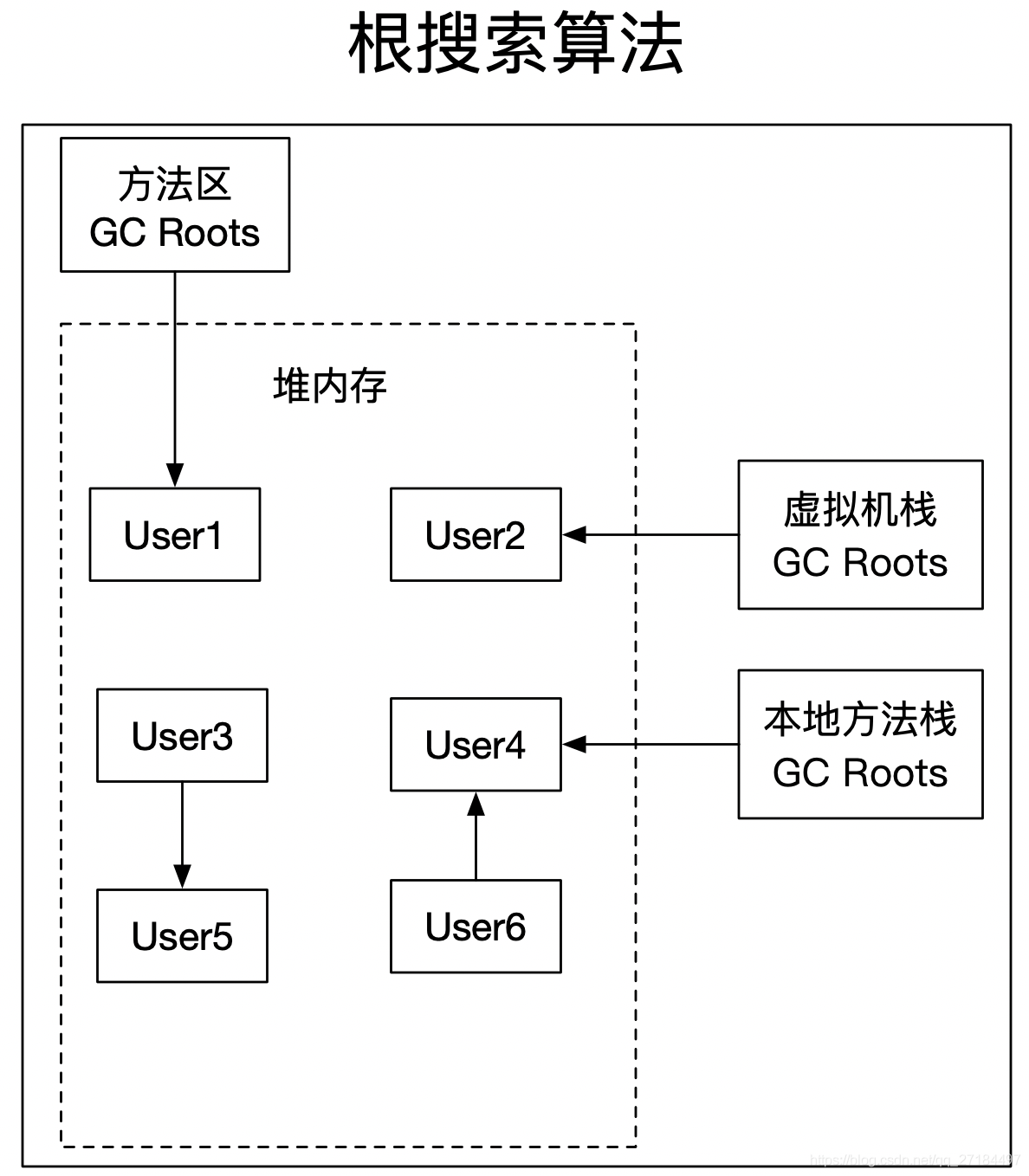
从上图,方法区、虚拟机栈、本地方法栈 都是GC Roots,可以看出:
- 方法区-> 对象实例User1;
- 虚拟机栈-> 对象实例User2;
- 本地方法栈 -> 对象实例User4;
- 本地方法栈 -> 对象实例User4 -> 对象实例User6;
可以得出对象实例1、2、4、6都具有GC Roots可达性,也就是存活对象,不能被GC回收的对象。
而对于对象实例3、5直接虽然连通,但并没有任何一个GC Roots与之相连,这便是GC Roots不可达的对象,这就是GC需要回收的垃圾对象。
5、复制算法
复制算法是为了解决效率问题而衍生出来的一种算法,顾名思义,就是以复制的形式进行垃圾回收,把原来的内存划分为大小相等的2块区域,每次只使用其中一块。当这一块的内存用完了,就将还存活着的对象复制到另外一块上面,然后再把已使用过的内存空间一次清理掉。这样使得每次都是对整个半区进行内存回收,内存分配时也就不用考虑内存碎片等复杂情况,只要移动堆顶指针,按顺序分配内存即可,实现简单,运行高效。只是这种算法的代价是将内存缩小为了原来的一半;复制算法的执行过程如下:
1、首先,实例化 2个对象,分别为 obj1 和 obj2 ,只要是new的对象一开始都被存放到 eden 区;
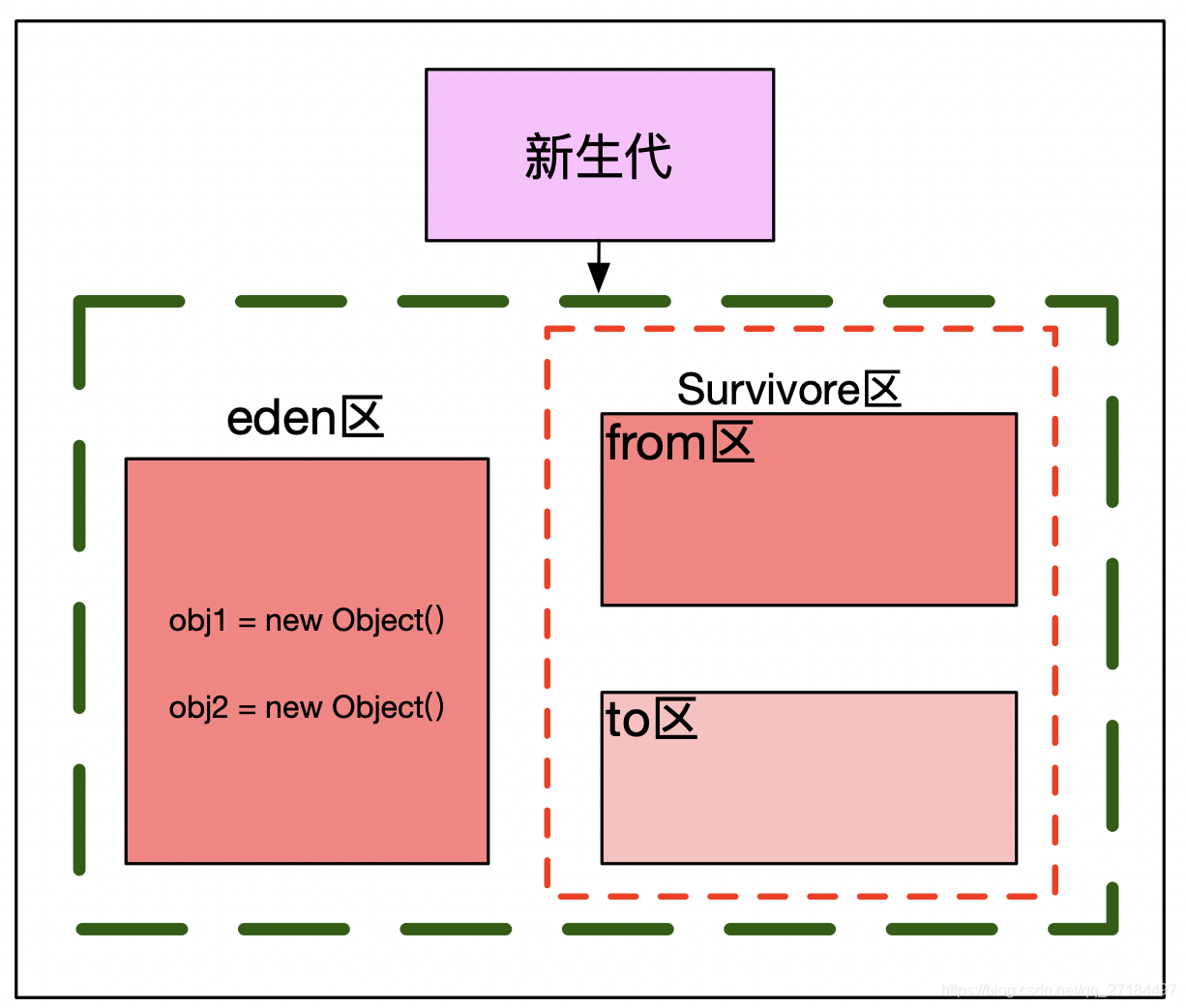
2、一段时间后,gc发现 obj1 和 obj2 都还在被引用,都是可达对象,此时将 obj1 和 obj2 移到 from区;
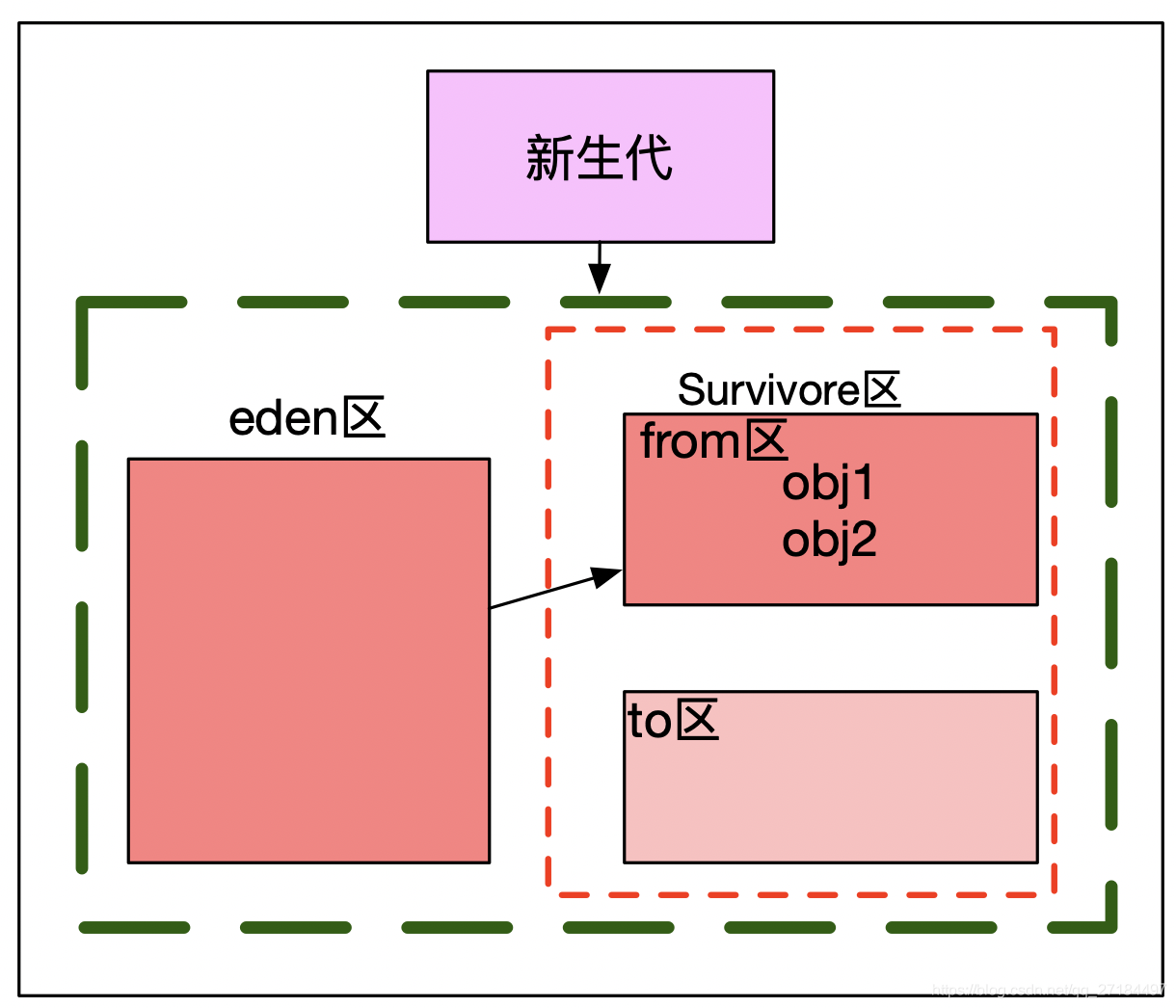
3、gc会不定时地清理from区的垃圾,扫描的时候时候发现 obj1 还是可达的对象, 但是 obj2 已经是不可达对象了,就会将 可达的 obj1复制到to去,同时清空from区
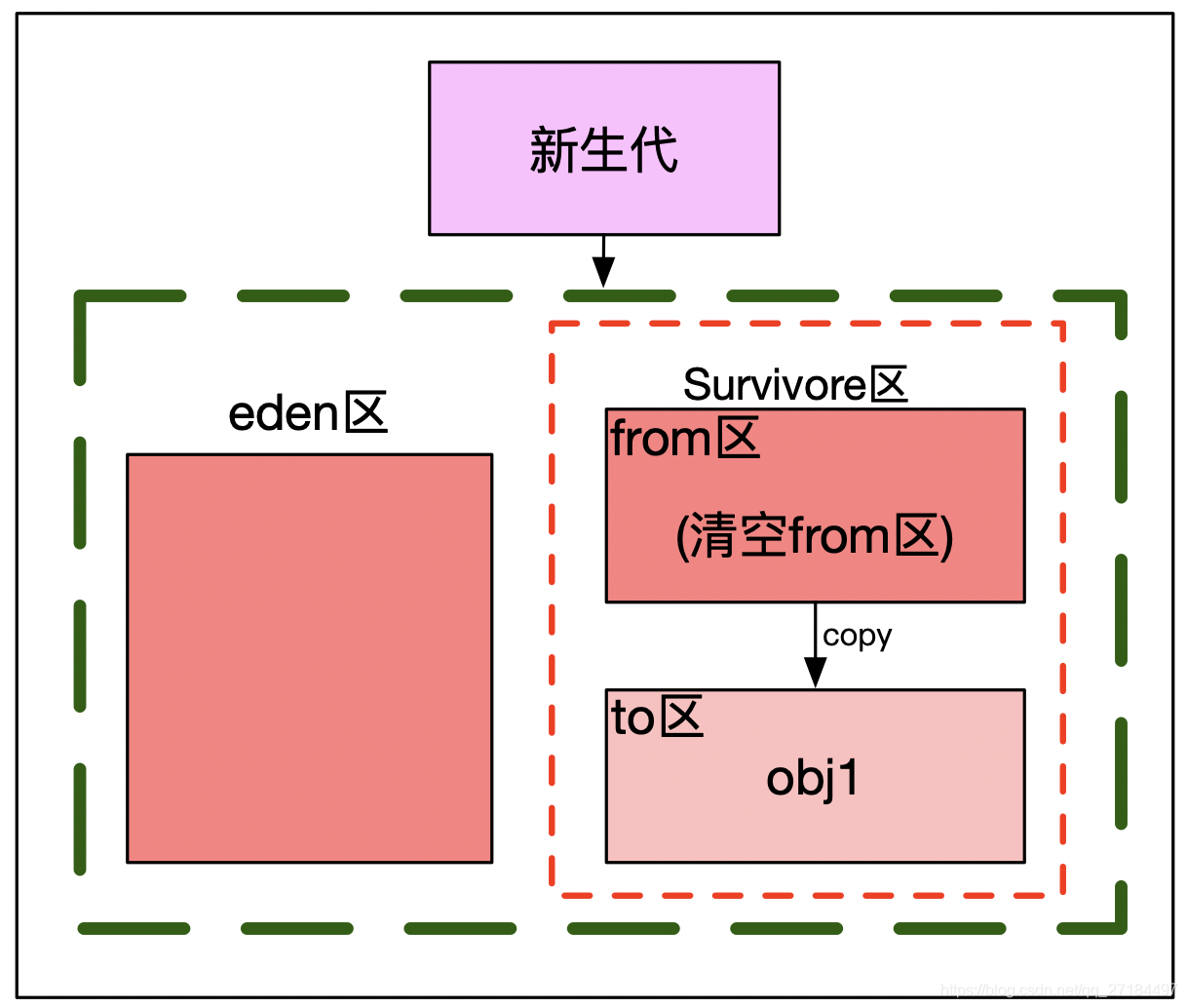
4、最后 obj1 已经到达15岁了,到了可以晋升的年龄,就会晋升到老年区,同时清空to区;
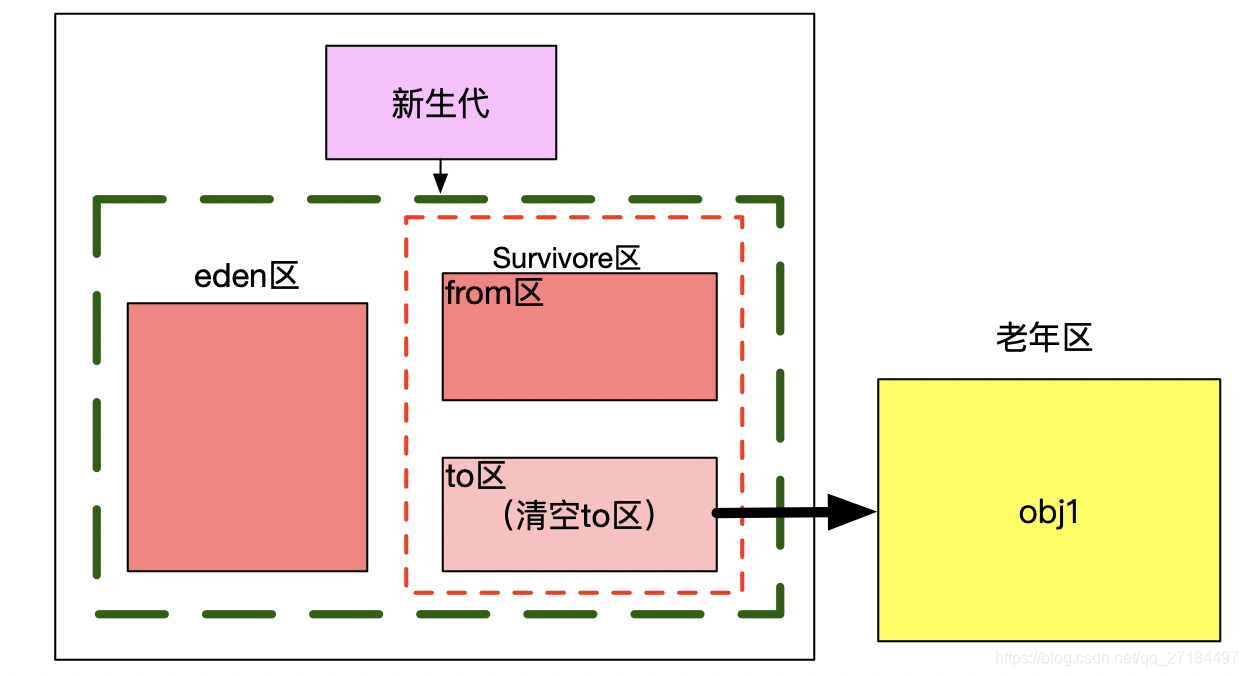
以上就是整个复制算法的晋升过程了,
6、分代算法
分代算法就相当于整合了以上每个算法,根据实际情况挑选出最合适的算法进行回收垃圾,根据对象的存活周期的不同将内存划分成几块,新生代和老年代,这样就可以根据各个年代的特点采用最适当的收集算法;
完
以上就是各种算法的详解和图解,各位观众朋友们,你看明白了吗?


