下载 1.15.1
https://flink.apache.org/downloads.html#apache-flink-1151
部署模式分类
- 会话模式
- 应用模式
- 单作业模式
1、会话模式
先启动一个集群,保持一个会话,然后通过客户端提交作业,所有作业都在一个会话执行;
会话模式适合规模小、执行时间短的大量作业;
2、应用模式
前两种模式应用代码都是在客户端运行,然后由客户端提交给jobmanager的,这种方式的弊端是:需要占用大量网络带宽,去下载依赖和把二进制数据发送给jobmanager,将会加重客户端资源消耗。
所以Application Mode的解决办法是:不需要客户端,直接把应用提交到jobmanager上运行,这意味着要为每个提交的应用单独启动一个jobmanager,也就是创建一个集群,
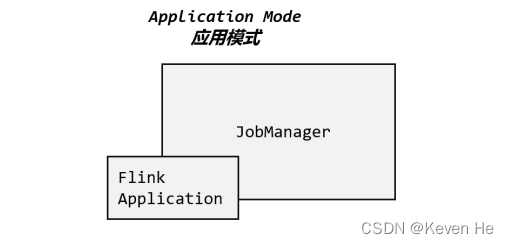
jobmanager执行完自己的应用将会关闭
应用模式与单作业模式,都是提交作业之后才创建集群;单作业模式是通过客户端来提交的,客户端解析出的每一个作业对应一个集群;而应用模式下,是直接由 JobManager 执行应用程序的,即使应用包含了多个作业,也只创建一个集群。此模式用的比较少,
3、单作业模式
为每个作业启动一个集群,只要客户端提交了一个作业,就为这个作业启动一个单独的集群,这个集群只为这个作业提供服务;其
一、独立会话模式(Standalone)-部署
flink只支持linux部署
1、解压
tar -zvxf flink-1.15.1-bin-scala_2.12.tgz
2、修改配置文件
vim conf/flink-conf.yaml# 修改以下内容jobmanager.rpc.address: 192.168.31.250 # 选择当前主机的ip地址,如果是云服务器,使用外网ip# JobManager将绑定到的主机接口,默认值为 localhost 禁止外部访问,设为0.0.0.0表示允许外部访问,设置错误的话 Available Task Slots 会显示0jobmanager.bind-host: 0.0.0.0# 任务插槽数量,相当于使用多少个线程来执行流taskmanager.numberOfTaskSlots: 2parallelism.default: 1web.submit.enable: true# 指定TaskManager主机的地址,单机部署的话,用localhost即可taskmanager.host: 192.168.31.250# web前端展示的端口,自己设置rest.port: 8081# 客户端应该用来连接到服务器的地址。注意:仅当高可用性配置为 NONE 时才考虑此选项rest.address: 192.168.31.250# 允许外部ip访问的地址,默认情况下是localhost,只能内部访问,改为0.0.0.0允许所有外部ip访问rest.bind-address: 0.0.0.0
3、修改master文件,
vim conf/masters# 填写主节点的ip地址,如果是云服务器,使用外网ip192.168.31.250:8081
4、修改 workers 文件
vim conf/workers# 添加 taskManager 节点的ip地址列表,如果是单节点,只填写主节点ip地址即可192.168.31.250192.168.31.251192.168.31.252
5、、启动
bin/start-cluster.sh
启动成功后,命令行会显示如下信息
[root@dev-server bin]# ./start-cluster.shStarting cluster. # 启动集群Starting standalonesession daemon on host dev-server. # 启动会话模式的 作业调度器 jobmanagerStarting taskexecutor daemon on host dev-server. # 启动任务管理器
通过jps命令可以看到已经启动的flink
[root@dev-server bin]# jps3010991 TaskManagerRunner # 任务调度器 taskManager3010438 StandaloneSessionClusterEntrypoint # 会话模式的节点3023395 Jps
说明:
- JobManager 的启动代码:standalonesession,实现类是:StandaloneSessionClusterEntrypoint
- TaskManager 的启动代码:taskexecutor,实现类是:TaskManagerRunner
6、、访问ui界面
http://192.168.31.250:8081
7、、停止flink
bin/stop-cluster.sh
二、提交作业
1、编写作业代码
新建maven项目,pom.xml 加入flink的依赖
<properties><java.version>1.8</java.version><scala-binary-version>2.12</scala-binary-version><flink-version>1.13.0</flink-version><slf4j-version>1.7.30</slf4j-version></properties><dependencies><!-- flink 依赖--><dependency><groupId>org.apache.flink</groupId><artifactId>flink-java</artifactId><version>${flink-version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-streaming-java_${scala-binary-version}</artifactId><version>${flink-version}</version></dependency><!-- flink 客户端,主要做一些管理相关的工作,如果不需要,就不需要导入此依赖--><dependency><groupId>org.apache.flink</groupId><artifactId>flink-clients_${scala-binary-version}</artifactId><version>${flink-version}</version></dependency><!-- 日志相关依赖--><dependency><groupId>org.slf4j</groupId><artifactId>slf4j-api</artifactId><version>${slf4j-version}</version></dependency><dependency><groupId>org.slf4j</groupId><artifactId>slf4j-log4j12</artifactId><version>${slf4j-version}</version></dependency><dependency><groupId>org.apache.logging.log4j</groupId><artifactId>log4j-to-slf4j</artifactId><version>2.14.0</version></dependency></dependencies>
2、编写java代码
package com.demo;/*** @author yexd*/import org.apache.flink.api.common.typeinfo.Types;import org.apache.flink.api.java.tuple.Tuple2;import org.apache.flink.streaming.api.datastream.DataStreamSource;import org.apache.flink.streaming.api.datastream.KeyedStream;import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;import org.apache.flink.util.Collector;/*** @title: 无界流处理* @Author yexd* @Date: 2022/8/7 20:10* @Version 1.0*/public class UnboundedStreamWord {static String ip = "192.168.31.250";static int port = 9879;/*** 先将文件中的每一行进行分词,然后统计每个单词出现的次数* @param args* @throws Exception*/public static void main(String[] args) throws Exception {// 创建执行环境StreamExecutionEnvironment executionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment();// 读取网络流,在linux系统输入命令 : nc -lk 8888 后,就可以进行通讯了,-lk表示保持当前的连接并持续监听8888端口DataStreamSource<String> stringDataStreamSource = executionEnvironment.socketTextStream(ip,port);// 将每行数据根据空格切割后进行分词,转换成二元组, FlatMapOperator<输入的数据类型, 输出的数据类型>SingleOutputStreamOperator<Tuple2<String, Long>> operator = stringDataStreamSource.flatMap((String line, Collector<Tuple2<String, Long>> out) -> {// 将每行进行切割String[] words = line.split(" ");for (String word : words) {// 将每个单词转换成二元组进行输出,其中第一个 word 表示单词本身, 1L表示每个单词出现的次数,后面会用这个次数来进行统计单词出现的总数out.collect(Tuple2.of(word, 1L));}});// 返回分词后的结果,FlatMapOperator<输入的数据类型, 输出的数据类型>SingleOutputStreamOperator<Tuple2<String, Long>> returns = operator.returns(Types.TUPLE(Types.STRING, Types.LONG));// 按照分词进行分组,keyBy 参数中的 f0 表示根据第几个字段进行分组(从0开始), 很明显,Tuple2的第一个字段是String类型,也就是刚刚分好词后的单词KeyedStream<Tuple2<String, Long>, Object> tuple2UnsortedGrouping = returns.keyBy(data -> data.f0);// 分组内进行聚合统计,sum 中的参数1 表示根据第几个属性进行统计,Tuple2<String, Long> 很明显第二个属性是Long,在上面我们将这个属性都置为1了,所以会进行统计SingleOutputStreamOperator<Tuple2<String, Long>> sum = tuple2UnsortedGrouping.sum(1);// 打印sum.print();// 启动执行executionEnvironment.execute();/**打印结果:4> (123,1)5> (hello,1)15> (456,1)5> (hello,2)4> (123,2)5> (hello,3)说明: 大于号前面的数字表示 线程的编号,表示使用不同的线程进行处理,也就是并行流*/}}
3、打包,通过以下命令将项目打成 jar 包
maven clean package
3、添加作业
在页面中选择 Submit New Job -> Add New ,
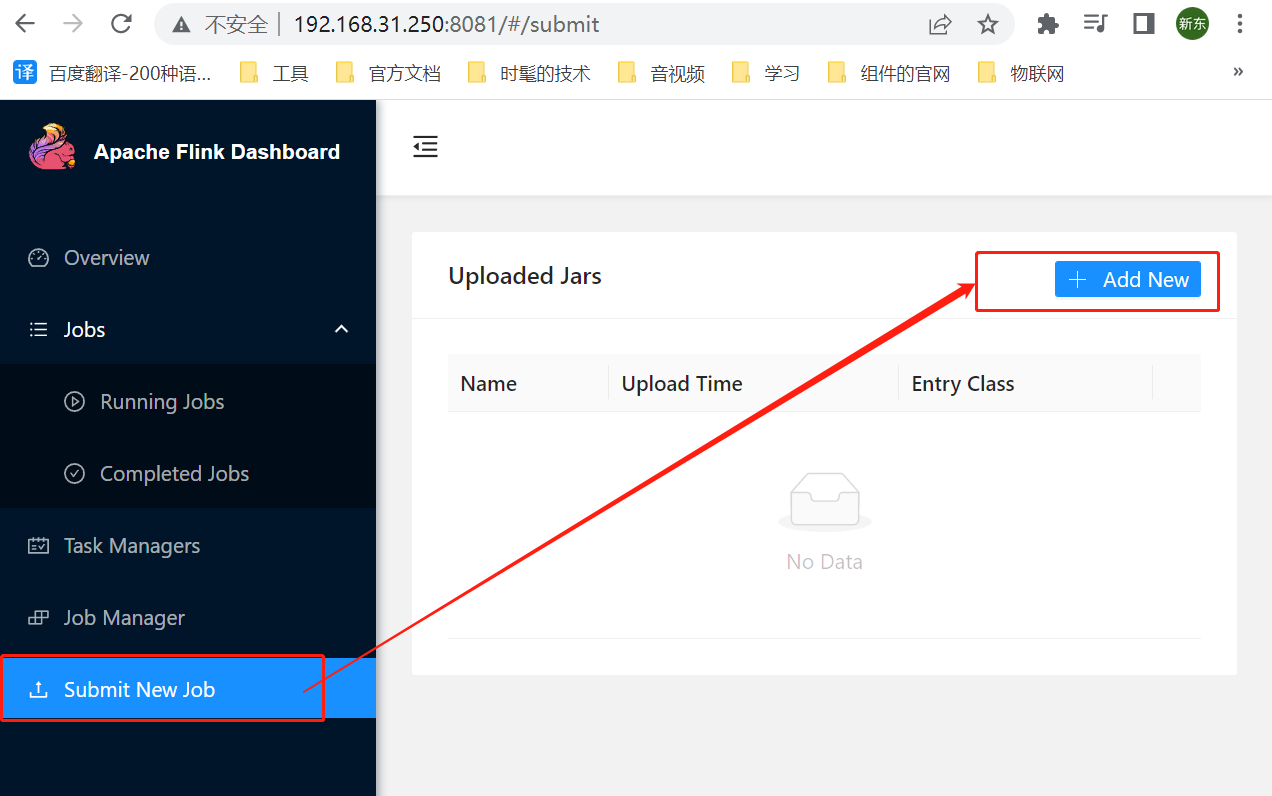
选择刚刚打好的jar包
上传后点击jar的名称,有些信息需要填写一下
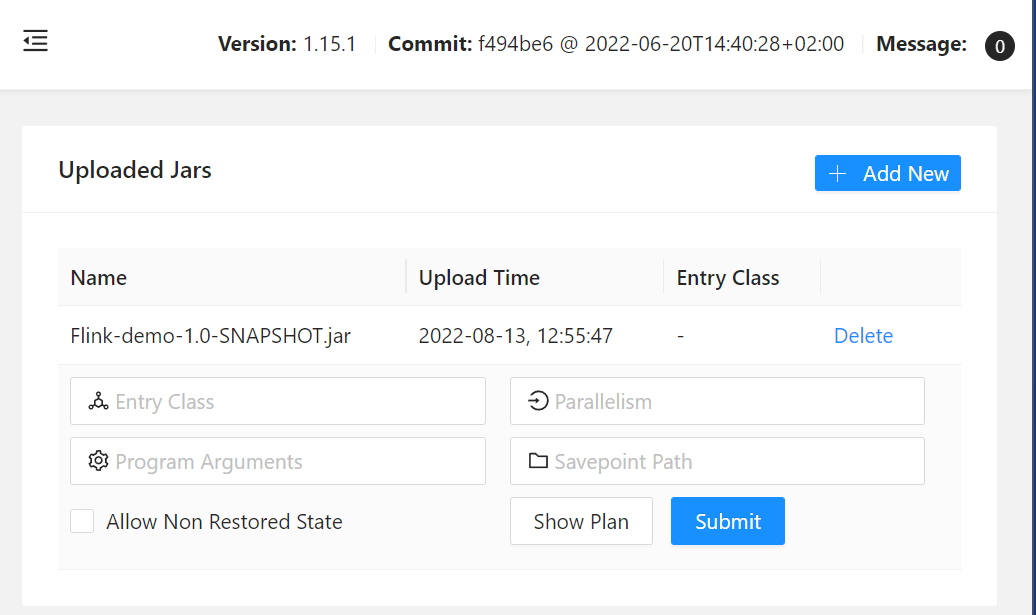
说明:
- Entry Class : jar包中 main 方法所在类的全类名
- Parallelism : 并行度,就是用多线程去执行作业,调成多少就用多少个线程执行作业
- Program Arguments : 传入main 方法的参数,多个参数用空格隔开
- Savepoint Path :保存点路径,比如你作业执行到一半,但是flink服务器需要重启,就会先暂停作业,然后将执行到一半的作业保存起来,待重启后继续执行,这里配置就是保存的路径;如果不需要保存,为空就行
4、提交之前的改动
因为在java代码里面用的无界流处理,也就是说,数据是通过 socket 网络传输的,如果不先启动监听的话,现在盲目提交就会导致报错,而我的代码里监听了 192.168.31.250 的 9879端口, 所以需要在 192.168.31.250 的服务器上输入以下命令来监听 9879 的端口
# -lk表示保持当前的连接并持续监听9879端口nc -lk 9879
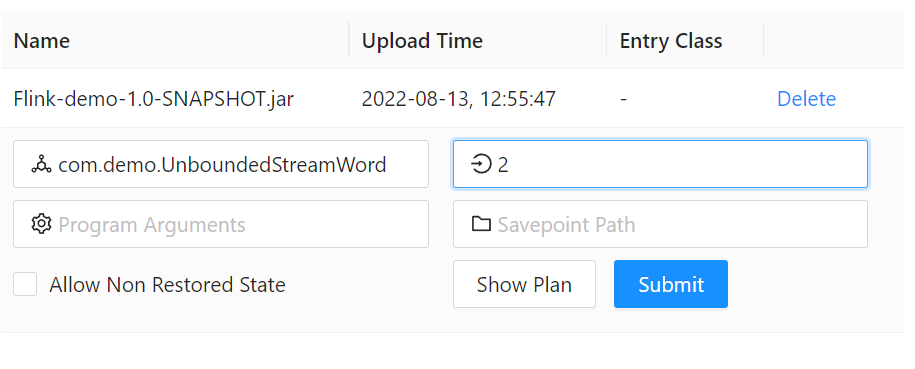
5、提交
以下是我的配置,然后点击 Submit 就可以提交了
提交后 一次点击左边的菜单栏 Jobs -> Running Jobs ,就可以可以看到刚刚提交的任务了,点进去看看
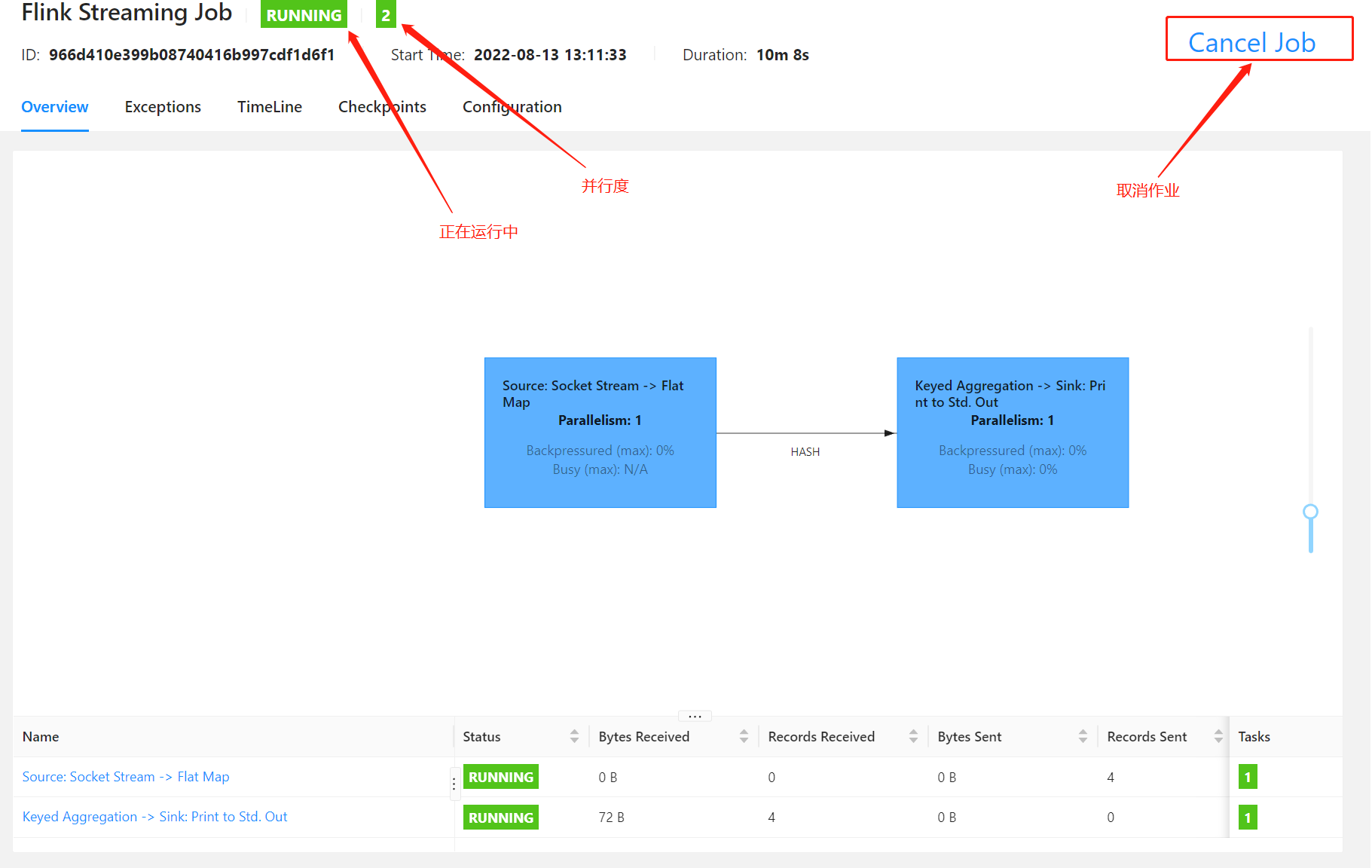
说明:
- 绿色的RUNNING 表示正在运行中,如果是红色的字体,就表示有错误
- RUNNING旁边绿色的 2 表示并行度,表示有2个线程执行这个作业
- 底部表格展示的是运行的时长、数据流大小、任务数量等信息
- Cancel Job : 可通过此按钮来停止作业
6、往flink发送消息
刚刚启动了 linux 监听了 9879 端口,发送了2条信息
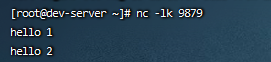
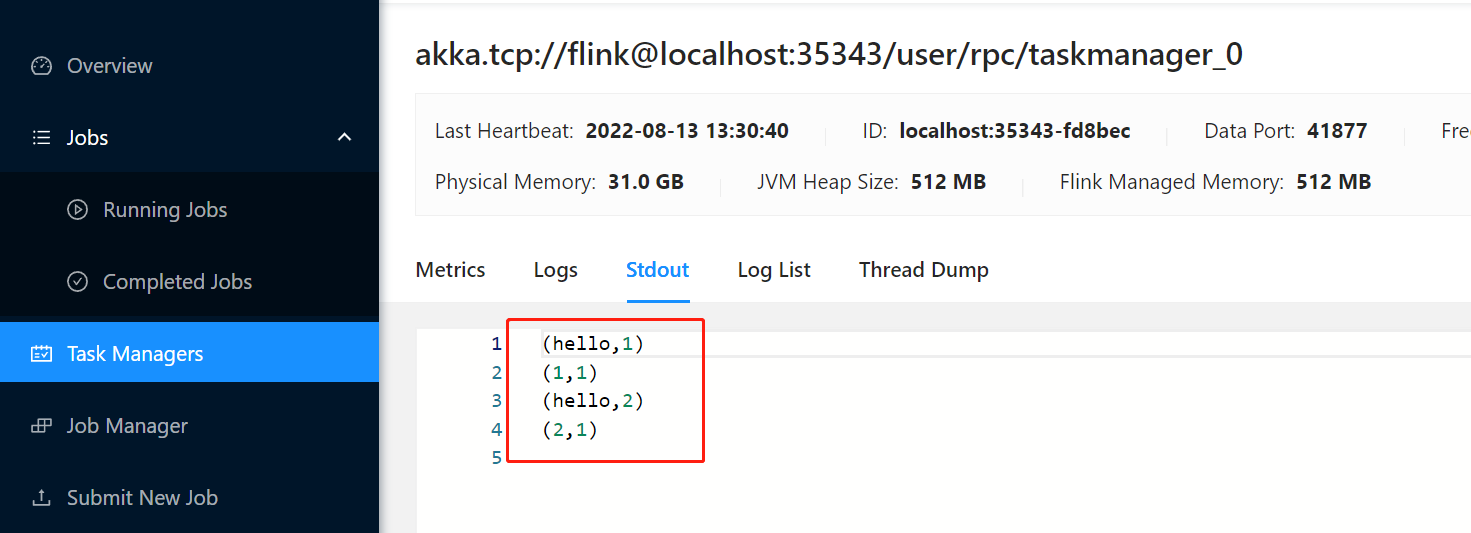
然后依次点击 TaskManager -> 任务id
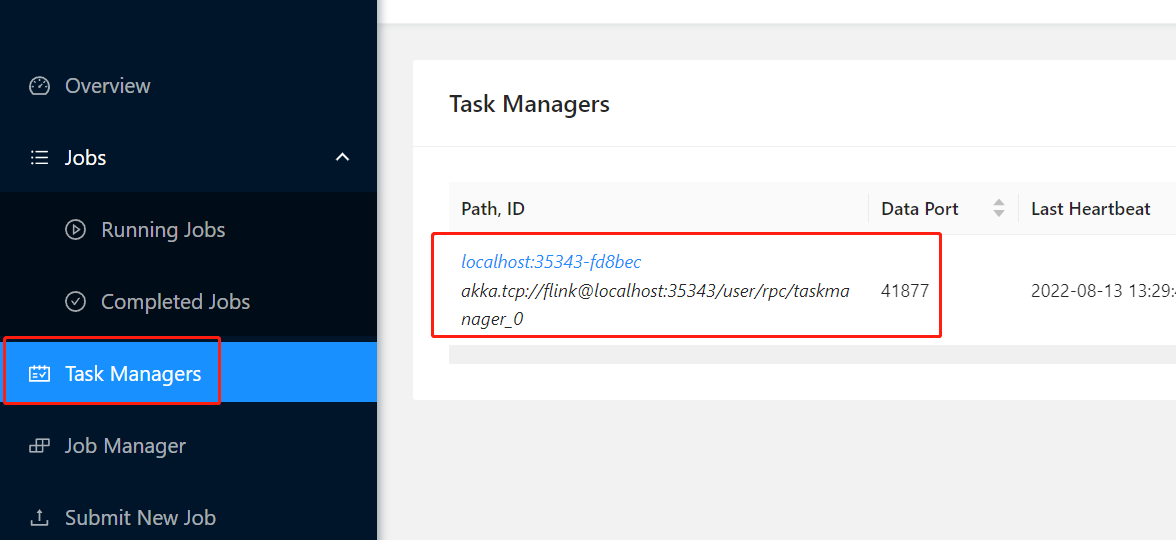
最后点击 Stout 就可以看到输入的内容了