1.内联函数的由来
当我们调用函数的时候,实际会有额外的开销,为了避免或减少这些额外的开销,c++中引入内联函数(inline functions)。
2.内联函数的原理
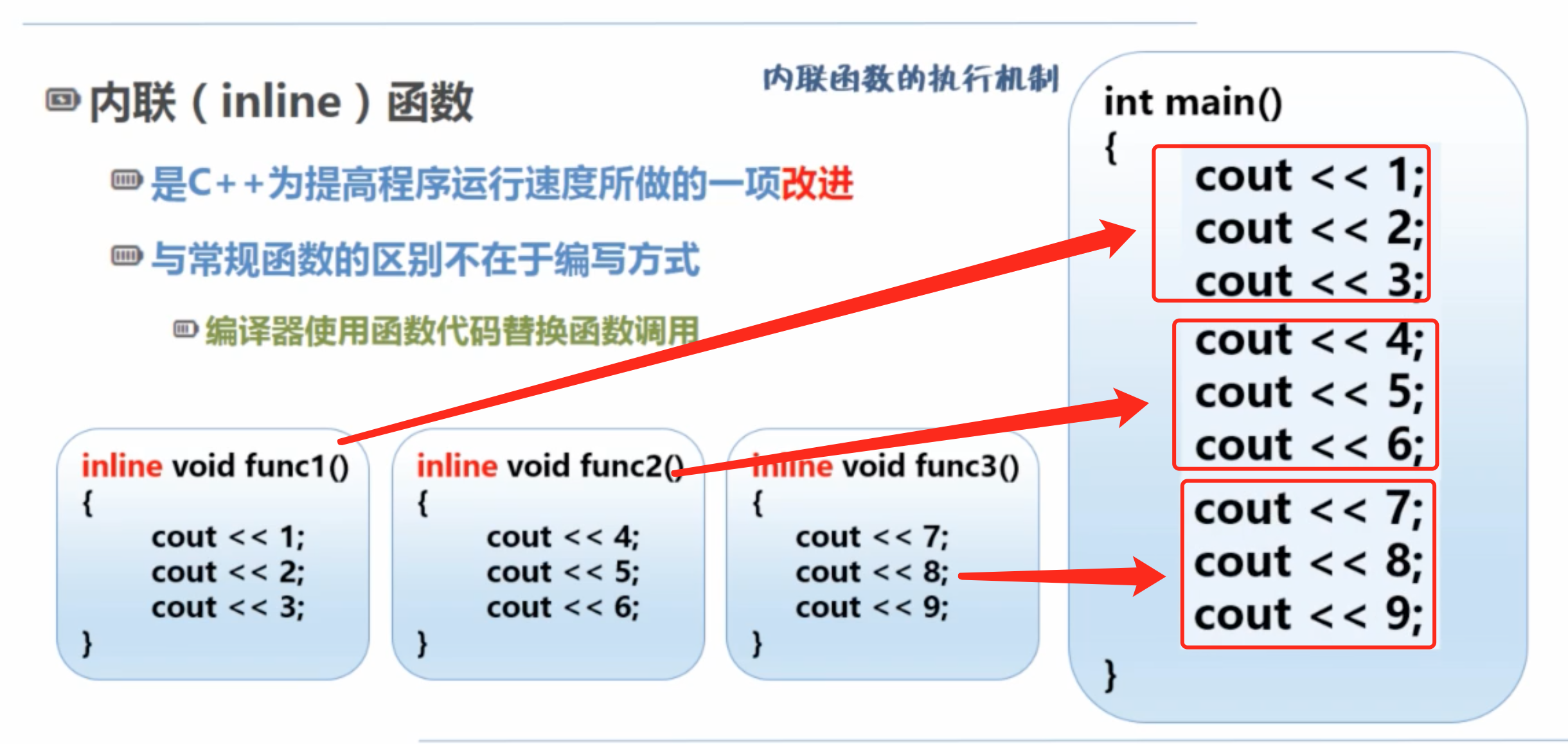
1)当我们调用内联函数时,不会像调用普通函数那样额外开销,而是把内联函数的代码直接嵌入到调用它的地方去,但仍然保持其独立性。
2)如果一个函数为内联函数,它就不会出现在最终的可执行代码里,只是会存在于编译器中,在编译器需要的地方插入。
替换前
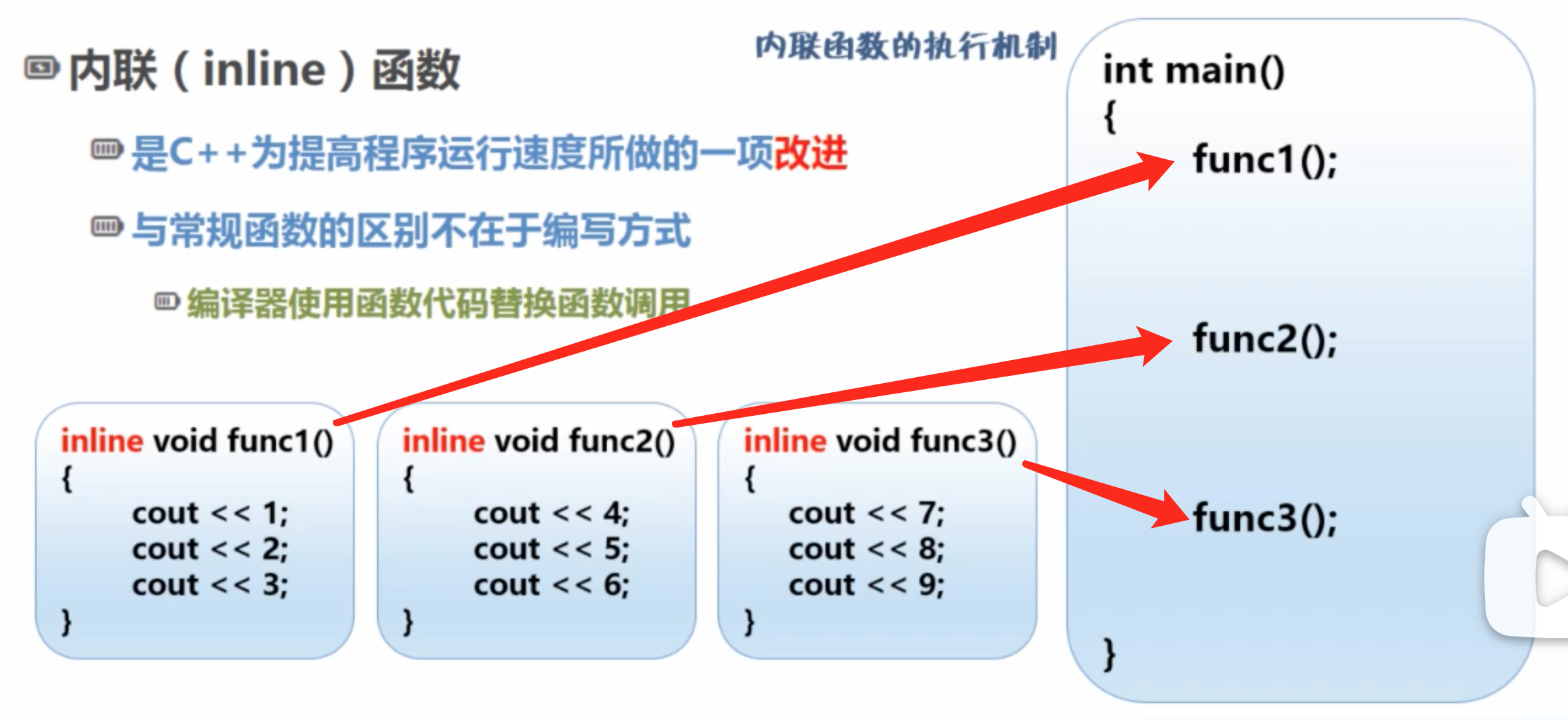
替换后
3.内联函数的写法
在一般函数前面加上inline的关键字,在头文件里定义而非声明。
#include "iostream"// inline 内联函数,又称内嵌函数或者内置函数。可以直接被main方法调用,// 内联函数一定要写在main方法的上面,否则main方法无法调用inline void func(){std::cout << "我是inlie函数" << std::endl;}int main() {func();std::cout << " " << std::endl;return 0;}// main方法无法调用 downFunc 内联函数,因为它在main函数的下面,inline void downFunc(){}
4.内联函数的优点
1)以牺牲代码的空间换时间,提高了效率。
2)与c语言的宏的思想类似,但要优于宏,因为宏不能做类型检查,而内联函数作为一个函数可以进行类型检查。
5.被自动默认的内联函数
1)在class声明中定义了成员函数,这些函数都是内联的。
2)如果我们为了使类看起来直观,在class中声明了成员函数,也可在class下方定义,将成员函数变为内联函数:
class a{private:int i;public:a();void f1();};inline a::a(){...}inline void a::f1(){...}
6.使用内联函数与否的情况
建议使用的情况:
1)函数代码本身较短,系统可能默认处理其为内联函数
2)频繁被调用的,处于循环中的函数
不能使用的情况:
1)过于巨大的函数,编译器可能拒绝该函数作为内联函数来插入
2)递归函数
7.内联函数和宏函数
内联函数的出现就是为了替代宏函数的,因为宏函数本身用起来不太方便,特别是多行宏函数,语法有点恶心,虽然底层都是替换;
宏函数的使用案例如下
#define add(n) n*nint main(){int res = add(10);std::cout <<res<< std::endl; // 打印结果为100int result = add(5+10);// 宏函数的原理是替换,所以以下代码中会被替换为 5+10 *5+10,结果为65,是不是很神奇(恶心)std::cout <<result<< std::endl;}
在看看多行宏函数的使用
// 定义多行宏函数--每一行结尾都需要有 \ 不需要写return#define addMayLine(n)({ \std::cout << "我是多行宏函数" << std::endl; \n*n; \});int main(){// 调用多行函数int s = addMayLine(2+3);// 替换后为:2+3*2+3,结果为11std::cout << s << std::endl;}
宏函数和内联函数相同点:
- 都可以节省函数调用的开销
宏函数和内联函数不同点
- 内联函数在编译时执行,而宏函数在预处理时执行。
- 宏定义不检查函数参数,返回值,只是展开;内联函数会检查参数类型
- 内联函数是真正的函数,只是在需要的时候,内联函数像宏一样展开,所以取消了函数的参数压栈。


