环境
系统:win10
opencv版本:3.4.16
资源下载
正负样本数据下载地址:https://download.csdn.net/download/qq_27184497/89512387
下载opencv:https://github.com/opencv/opencv/releases/
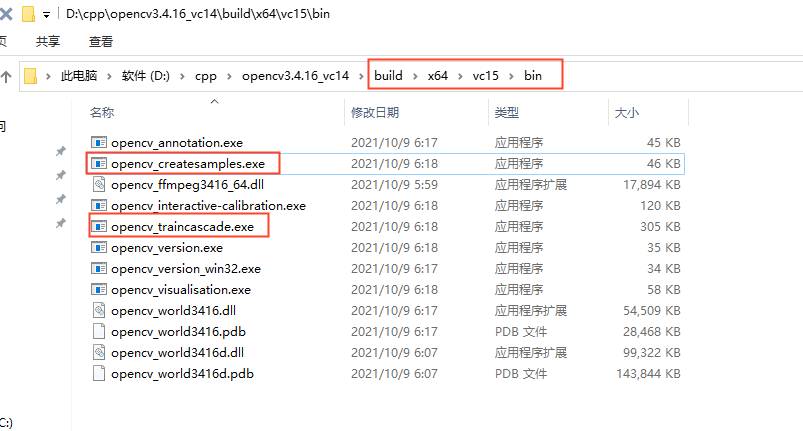
下载好 opencv 的windows版本后,在 build\x64\vc15\bin 目录下会有 以下2个文件
- opencv_createsamples.exe: 用于创建样本集,生成正样本和负样本,以供级联分类器的训练使用。它将正样本和负样本的图像作为输入,并生成一个用于训练的样本描述文件(.vec 文件)。正样本是包含目标对象的图像块,而负样本则是不包含目标对象的图像块。
- opencv_traincascade.exe :用于训练级联分类器模型,该模型由多个强分类器组成,每个强分类器都是由多个弱分类器级联而成。训练级联分类器是一个迭代的过程,它通过逐步增加弱分类器并进行训练来提高检测性能。在训练过程中,它使用样本描述文件(.vec 文件)和负样本图像来进行训练,并输出一个训练好的级联分类器模型文件。
生成正样本集
准备好样本数据,下载以上样本数据后会得到以下红框内的文件,因为我已经训练过了,所以会多出来几个已经训练好的文件;
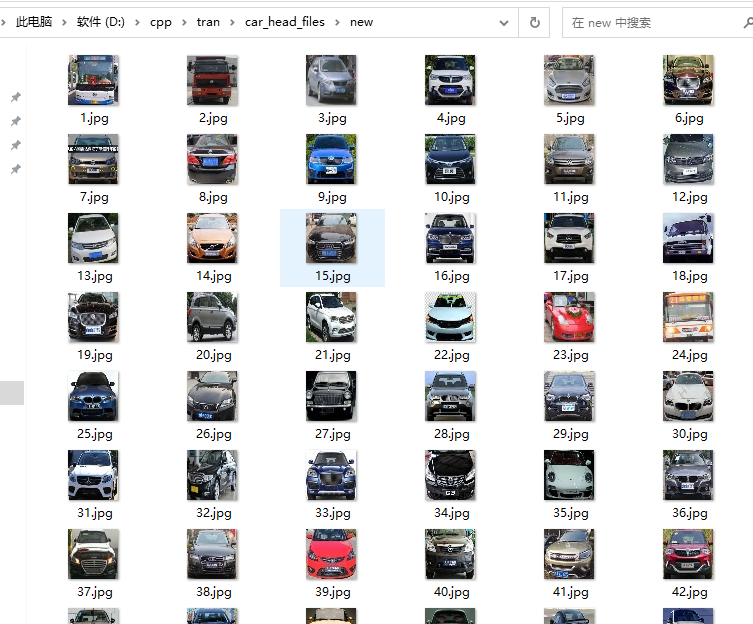
需要训练的是一些车头的图片,并且是经过转换后的,因为原图太大了,训练的时候会很慢,所以我将所有的车头都转为 50*50像素的小图,这样可以加快训练速度;
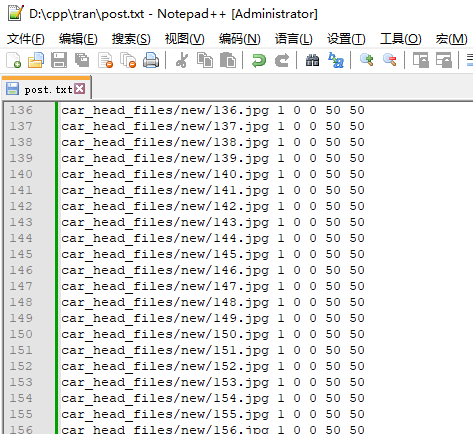
在看一眼正样本数据文件,里面存放了所有正样本数据的相对路径,注意后面的(1 0 0 50 50),我挨个解释下
(检测目标个数 + 目标图片左上位置坐标x + y + 图片宽高 width + height)
首先进入 当前tran 目录
D:\cd cpp\tran
输入以下命令生成样本集 vec文件
D:\cpp\opencv3.4.16_vc14\build\x64\vc15\bin\opencv_createsamples.exe -info post.txt -vec ./pos.vec -num 192 -w 50 -h 50
参数说明:
opencv_createsamples.exe: 生成样本描述文件的可执行程序(opencv自带),前面是我电脑上的路径。
-vec ./pos.vec 指定在当前目录生成vec文件
-info post.txt 指定源样本的描述文件
-num 192 指定标定目标样本总数量,就是正样本描述文件里所有第2列的数字之和。
-w 50 指定样本缩放后的宽,如果之前图片不是50,那么这里就会缩放成50,有了这个参数就可以省去之前的图片处理过程。
-h 50 指定样本缩放后的高,如果之前图片不是50,那么这里就会缩放成50,有了这个参数就可以省去之前的图片处理过程。
若展示以下信息,则表示样本集已经生成;
D:\cpp\tran>D:\cpp\opencv3.4.16_vc14\build\x64\vc15\bin\opencv_createsamples.exe -info post.txt -vec ./pos.vec -num 192 -w 50 -h 50Info file name: post.txtImg file name: (NULL)Vec file name: ./pos.vecBG file name: (NULL)Num: 192BG color: 0BG threshold: 80Invert: FALSEMax intensity deviation: 40Max x angle: 1.1Max y angle: 1.1Max z angle: 0.5Show samples: FALSEWidth: 50Height: 50Max Scale: -1RNG Seed: 12345Create training samples from images collection...Done. Created 192 samples
此时会在当前目录下多了pos.vec文件
打开后里面是乱码的,咱也不知道是啥
开始训练
训练之前先说明一下: 负样本不需要生成vec文件;所以,直接开始训练吧!
输入以下命令进行训练,因为负样本比较多,所以训练的时间会比较长,几个小时起步吧!耐心点
D:\cpp\opencv3.4.16_vc14\build\x64\vc15\bin\opencv_traincascade.exe -data ./ -vec ./pos.vec -bg bg.txt -numPos 192 -numNeg 1964 -numStages 20 -w 50 -h 50 -model ALL
参数说明:
-data 指定输出目录,训练生成的xml文件就放在这个目录下, ./ 表示输出到当前目录下
-vec 指定正样本生成的 vec 文件,就是刚刚生成的正样本集
-bg 指定负样本数据文件,即前面下载的neg.txt文件
-numPos 指定正样本数目,这个数值一定要比准备正样本时的数目少,不然会报 can not get new positive sample。
- 参考理由:minHitRate:影响每个强分类器阈值,当设置为0.95时如果正训练样本个数为10000个,那么其中的500个就很可能背叛别为负样本,第二次选择的时候必须多选择后面的500个,按照这种规律我们为后面的每级多增加
numPos*minHitRate个正样本,根据训练的级数可以得到如下公式: numPos+(numStages-1)*numPos*(1-minHitRate)<=准备的训练样本,- 以上式子也只是根据训练级数和准备的正样本总和设置一个参与训练的正样本个数,只能作为估算,小于计算出来的数可能没有问题,但是大于那个数肯定有问题
- 现在解释下”可能有问题“是如何理解的:因为我们总是默认每次添加固定个数的正训练样本,但是有时候后面的固定个数的正训练样本中也可能存在不满足条件的样本,这些样本跟我们排除的样本类似,所以比如我们打算添加500个样本就够了,但是实际需要添加600个,这时候就出现问题了。
- 从上面例子的结果中可以看出,每级我们允许丢掉12000*0.001个正样本=12,需要注意的是万一第11个或者第10个跟第12个的阈值是一样的,那么我们之丢掉了前面的10个或者9个而已,因此每次增加的个数可能要小于12个,大于12个的情况就是上面所说的”可能有问题“。
- 参考理由:minHitRate:影响每个强分类器阈值,当设置为0.95时如果正训练样本个数为10000个,那么其中的500个就很可能背叛别为负样本,第二次选择的时候必须多选择后面的500个,按照这种规律我们为后面的每级多增加
-numStages 指定训练阶段数量, 较低的值会导致一个较简单的分类器,训练速度可能较快,但检测性能可能较低。较高的值会导致一个更复杂的分类器,训练时间可能更长,但检测性能可能更好; 默认值为 20。一般取值15~25
-numNeg 指定负样本数目
-w 40 -h 40 指定样本图尺寸
-mode 指定训练模式
-mode BASIC:基本训练模式。在基本模式下,opencv_traincascade.exe将使用单个核心执行训练任务。这是默认的训练模式,适用于较小的数据集和简单的训练任务。-mode ALL:全面训练模式。在全面模式下,opencv_traincascade.exe将尽可能地利用系统中的所有可用核心进行并行训练,以加快训练速度。这适用于较大的数据集和复杂的训练任务。
- -featureType 配置级联分类器所使用的特征类型,有以下可选值
HAAR(默认值):使用 Haar-like 特征。Haar-like 特征是一种基于矩形区域的特征表示方法,常用于人脸检测等任务。LBP:使用局部二值模式(Local Binary Patterns,LBP)特征。LBP 特征是一种基于图像纹理的描述方法,适用于人脸检测、纹理分类等任务。HOG:使用方向梯度直方图(Histogram of Oriented Gradients,HOG)特征。HOG 特征是一种基于梯度方向的图像描述方法,常用于行人检测等任务。
没训练完一个阶段都会提示,并且告诉你总共训练的用时情况
D:\cpp\tran>D:\cpp\opencv3.4.16_vc14\build\x64\vc15\bin\opencv_traincascade.exe -data ./ -vec ./pos.vec -bg bg.txt -numPos 192 -numNeg 1964 -numStages 20 -w 50 -h 50 -mode ALLPARAMETERS:cascadeDirName: ./vecFileName: ./pos.vecbgFileName: bg.txtnumPos: 192numNeg: 1964numStages: 20precalcValBufSize[Mb] : 1024precalcIdxBufSize[Mb] : 1024acceptanceRatioBreakValue : -1stageType: BOOSTfeatureType: HAARsampleWidth: 50sampleHeight: 50boostType: GABminHitRate: 0.995maxFalseAlarmRate: 0.5weightTrimRate: 0.95maxDepth: 1maxWeakCount: 100mode: BASICNumber of unique features given windowSize [50,50] : 3024775===== TRAINING 0-stage ===== // 第0个阶段<BEGINPOS count : consumed 192 : 192NEG count : acceptanceRatio 1964 : 1Precalculation time: 1.901+----+---------+---------+| N | HR | FA |+----+---------+---------+| 1| 1| 1|+----+---------+---------+| 2| 1| 1|+----+---------+---------+| 3| 1| 1|+----+---------+---------+| 4| 1| 0.735234|+----+---------+---------+| 5| 1| 0.543788|+----+---------+---------+| 6| 1| 0.549389|+----+---------+---------+| 7| 1| 0.387984|+----+---------+---------+END>Training until now has taken 0 days 0 hours 30 minutes 19 seconds. // 从开始训练迄今为止花费了30分钟19秒===== TRAINING 1-stage ===== // 第1个阶段<BEGINPOS count : consumed 192 : 192NEG count : acceptanceRatio 1964 : 0.381507Precalculation time: 1.956+----+---------+---------+| N | HR | FA |+----+---------+---------+| 1| 1| 1|+----+---------+---------+| 2| 1| 1|+----+---------+---------+| 3| 1| 1|+----+---------+---------+| 4| 1| 0.697047|+----+---------+---------+| 5| 1| 0.630346|+----+---------+---------+| 6| 1| 0.485743|+----+---------+---------+END>Training until now has taken 0 days 0 hours 58 minutes 3 seconds.===== TRAINING 2-stage ===== // 第2个阶段...... 中间忽略===== TRAINING 17-stage ===== 第N个阶段<BEGINPOS count : consumed 192 : 192NEG count : acceptanceRatio 0 : 0Required leaf false alarm rate achieved. Branch training terminated.
这里需要注意下, 本来需要训练20个阶段的,但是训练到第17个阶段就结束了,花了将近30个小时,还是挺久的,并且最底部提示了个信息:
Required leaf false alarm rate achieved. Branch training terminated.
解析:
虚警率已经达标 不再继续训练,这里不能说是一个错误,只能说制作出来的xml文件可能较差, 其实就是样本太少了,生成的模型质量不行,
解决方案:
先测试一下生成的cascade.xml,如果效果没有达到你的预期 有以下几个解决方案:
- 正负样本数太少,增大样本数
模型测试
新建 CMakeLists.txt 文件,内容如下
cmake_minimum_required(VERSION 3.27)project(face_recognition)set(CMAKE_CXX_STANDARD 11)# 设置OpenCV的路径(根据你自己的安装路径进行更改)set(OpenCV_DIR "D:\\cpp\\opencv3.4.16_vc14\\sources\\build")find_package(OpenCV REQUIRED)include_directories(${OpenCV_INCLUDE_DIRS})add_executable(${PROJECT_NAME} main.cppface_person.cppface_person.h)target_link_libraries(${PROJECT_NAME} ${OpenCV_LIBS})
在新建一个main.cpp 文件
// 识别图片中的车头void readImg() {// 加载分类器cv::CascadeClassifier faceCascade;// 加载分类器,选择你刚刚训练好的分类器文件路径faceCascade.load("D:\\cpp\\tran\\cascade.xml");Mat src;// 初始化一个操作对象src = imread(R"(D:\Users\w9033927\Pictures\fd604550d054ef631b655b367dc86e1c.jpg)", 1);// 自己找一张图片,路径不能有中文//检测图像是否加载成功, //检测image有无数据,无数据 image.empty()返回 真if (src.empty()) {cout << "不能加载图片" << endl;return;}// 创建窗口cv::namedWindow("Face Detection", cv::WINDOW_NORMAL);// 宽度和高度double width = src.cols;double height = src.rows;// 打印图片的宽度和高度std::cout << "大小: " << width << " x " << height << std::endl;const char *windowName = "Face Detection";// 创建一个窗口cv::namedWindow(windowName, cv::WINDOW_NORMAL);// 设置窗口的大小cv::resizeWindow(windowName, width * 0.3, height * 0.3);cv::Mat frame = src.clone();if (frame.empty()) return;// 将彩色图像转换为灰度图像以加快处理速度cv::Mat grayFrame;cv::cvtColor(frame, grayFrame, cv::COLOR_BGR2GRAY);// 对图像进行物体检测std::vector<cv::Rect> faces;faceCascade.detectMultiScale(grayFrame, faces, 1.1, 3, 0, cv::Size(30, 30));// 在图像上绘制物体的边界框for (size_t i = 0; i < faces.size(); i++) {auto item = faces[i];printf("h:%d, w:%d ,x:%d, y:%d\n",item.height,item.width,item.x,item.y);cv::rectangle(frame, faces[i], cv::Scalar(0, 255, 0), 3);}// 显示结果图像cv::imshow(windowName, frame);waitKey(0);// 释放资源src.release();frame.release();// 释放窗口资源cv::destroyAllWindows();}int main() {readImg();return 0;}
经过我测试后发现这个模型的识别能力也还可以,至少可以满足我的需求;因为是学习嘛,要求不要太高;

如果需要这个训练好的模型的话,可以扫旁边的二维码加我微信领取;或者留言也行!


